
Любишь ли ты тест: Тест на любовь к парню

Любишь ли ты его? И любит ли он тебя?)) — Трикки — тесты для девочек
Привет! Этот тест разбит на две части, в одном тесте. Первая половинка будет спрашиваться на тему, любишь ли ты ЕГО, а вторая половинка покажет любит ли ОН тебя. Я не экстрасенс, тапками обильно не кидаться. Если результат выпадет который тебе не по душе, не расстраивайся, это лишь тест) хотя, не исключено, что тут будет 90% правды.
Вопрос 1.
Привет. Начнём! Эта половинка, предупреждаю, покажет любишь ли ты ЕГО. Первый вопрос. Как часто ты думаешь о нём?
Очень редко/редко/вообще никогда
Иногда/частенько
Часто/очень часто!
Вопрос 2.
Ты знакома с ним?
Нет
Ну, так..
Да, конечно
Вопрос 3.
А дружишь ли?
Нет, мы враги/не дружим/не знакомы
Вроде бы да/ДРУГОЕ
Да, дружим/мы лучшие друзья
Вопрос 4.
А вообще, какие у вас нынче отношения?
Плохие/нейтральные/никакие, мы не знакомы
Неплохие/хорошие, вроде бы жаловаться не на что, но хотелось бы лучше. Мы иногда играем вместе, но в компании, веселимся, прикалываемся над другими, а иногда можем и игнорировать друг-друга/ДРУГОЕ
Мы иногда играем вместе, но в компании, веселимся, прикалываемся над другими, а иногда можем и игнорировать друг-друга/ДРУГОЕ
Классные! Мы веселимся, гуляем, даже иногда наедине, дружим классно!
Вопрос 5.
Представь его, и другую девочку,или даже твою подругу. Твои чувства?
И что? Пусть дальше с ней флиртует. Мне всё равно
Не очень приятно/ДРУГОЕ
О-о! Как же я ревну… стоп, что?! я ревную?! кажется.. да!!!/о, я ревную не по-детски!
Вопрос 6.
Ты смущаешься при нём?
Нет 🙁
Немного 🙂
Да! :))
Вопрос 7.
Представь, он, (тот самый твой принц), заговорил с тобой/предложил дружить/предложил погулять/заступился за тебя и другое, твои чувства?
Ну и что?
Приятно))/ДРУГОЕ
О!! Как я рада! Ура! Ура! Он обратил на меня внимание!! О, Боже!! Я на седьмом небе от счастья!!!
Вопрос 8.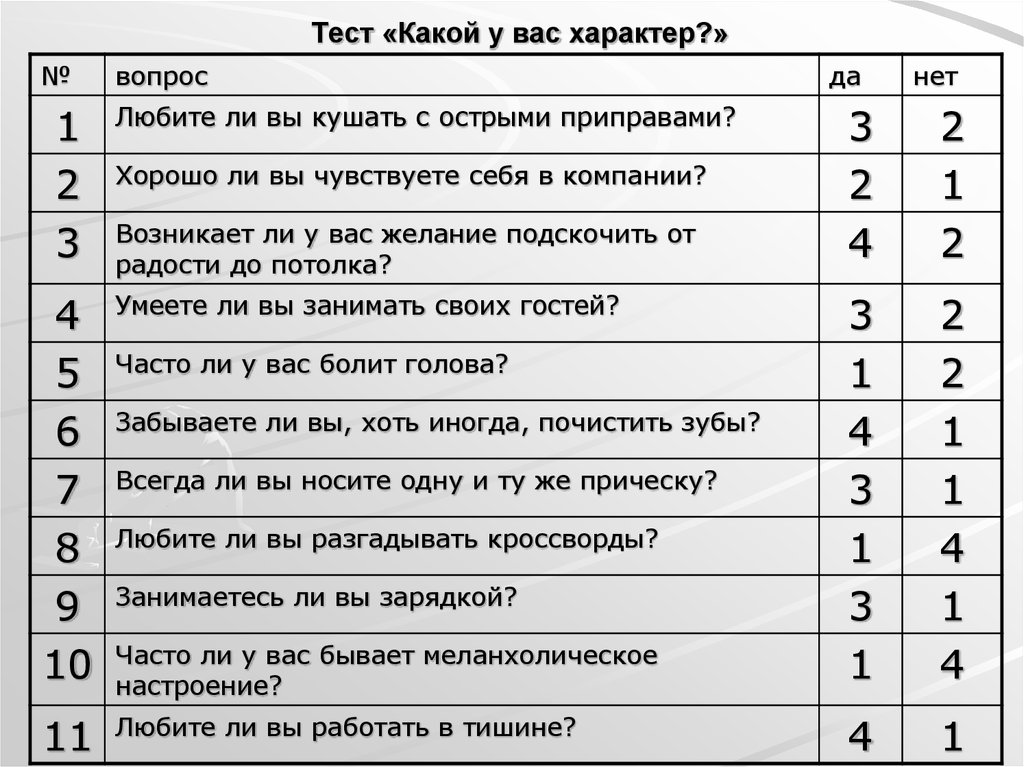
Какие мысли о нём приходят в твою голову?
Никакие/просто мелькнуло в голове его имя, и всё
Немного представляю его с собой, и мне так хорошо на душе/ДРУГОЕ
Я представляю его в романтическом плане. Как мы целуемся, обнимаемся, женимся, дружим, гуляем, на свидании встретились, и так далее
Вопрос 9.
Ты гадала на него?
Что?! Я подобной фигнёй не страдаю
Иногда пробовала/ДРУГОЕ
Да!/О, да, я все гадания уже на него использовала!
Вопрос 10.
Тебе приходила мысль в голову, подобие такого: «Как бы я хотела (его имя) соблазнить!»?
Нет! Пф! Что за чушь!/у нас может быть дружба, но не любовь
Иногда посещала)))/ДРУГОЕ
Да! Я заморачиваюсь целые сутки над этим!
Вопрос 11.
Кто он для тебя?
Простой прохожий/знакомый
Одноклассник/друг/приятель/ДРУГОЕ
Лучший друг/скрытый поклонник/парень/с параллели/другой школы/другого города/другой страны/знакомый с Интернета
Вопрос 12.
Теперь вторая половинка. Эта половинка покажет любит ли он тебя. Итак, первый вопрос. Он обращает на тебя внимание, и если да, то как?
Никак он не обращает на меня внимание
Иногда смотрит, говорит и т.п. /ДРУГОЕ
О! Он всегда общается со мной, мы гуляем, играем, веселимся, шутим и т.п./У нас умеренно. Чаще всего мы можем погулять в компании, повеселиться, но иногда бывает застой(
Вопрос 13.
Был ли у вас флирт когда-то? (пример: подмигивание, улыбка, простой взгляд, милая беседа, лёгкие кивки головой и т.п.)
Нет
Однажды случайно было/бывает/ДРУГОЕ
Зачастую/часто/очень часто
Вопрос 14.
Часто ли у вас происходят прикосновения?
Что?! Да пошел он! Нет, конечно
Иногда/бывает/ДРУГОЕ
Зачастую/часто/очень часто
Вопрос 15.
Что между вами: ненависть(вражда), дружба, симпатия или любовь(скорее, влюблённость), или ничего? Подумай хорошо над этим вопросом
Ненависть (вражда)/Ничего
Дружба! Может, лёгкая симпатия/только дружба/ДРУГОЕ
Симпатия/влюблённость
Вопрос 16.
Есть ли у тебя соперницы?
Нет/есть, у меня нет шансов
Немного есть/ДРУГОЕ
Есть, но я сильнее чем они
Вопрос 17.
Вы гуляли когда-то вместе?
Нет! О чём вы шепчете, мадам, если мы не знаем друг-друга/ненавидим друг-друга??
В компании только/нет, ещё не гуляли/ДРУГОЕ
Да!
Вопрос 18.
Представь, у вас урок физкультуры. Мальчикам дали мяч, и они пошли играть в футбол, а девочкам дали мячики, скакалки, обручи и всё такое (лично, так у нас на уроках физкультуры), и вот уже мальчики играют, ты смотришь на поле и…
Ничего! Что, и? Я должна с танцами орать: «Мой (его имя), выиграй пожалуйста!». да ну его!!
Я вижу много одноклассников. Бывает частенько что ОН бросается мне в глаза (имею в виду, не как кошка собаке, а то есть, я его сразу могу выделить с общей массы)
О! Я его сразу замечаю на горизонте всех одноклассников!
Вопрос 19.
Он делал для тебя что приятное?
Пф, нет/одну фигню делал
Нет, такого ничего не делал/ДРУГОЕ
Заступился/поделился чем-то/позвал играть и т.п.
Ты любишь его по-настоящему?
Автор теста: semkovi4kristina
1. Ну ладно, опиши мне его.
Он… Он потрясающий… Добрый, красивый, умный, смешной… Он такой… Неповторимый…
Он прекрасный человек.
Нормальный он.
2. Поскольку представить безумство самой не очень просто, я приведу пример. Его схватили какие-то маньяки, убийцы. Позвонив на первый попавшийся номер на его телефоне (он оказался твоим), они говорят: ”Ты должна отдать свою жизнь, если хочешь, чтобы он выжил!”. Ты пойдешь ради его спасения?
Я пойду! Сразу! Потому что он должен жить!
Может, лучше позвонить в полицию? Я не готова совершить такую глупость!
А откуда у него мой номер? О_О
3. Что ты больше всего желаешь ему?
Что ты больше всего желаешь ему?
Я желаю ему БЫТЬ… Быть счастливым… Быть богатым… Быть любимым… А главное, быть Человеком.
Я желаю ему всего самого наилучшего, я хочу, чтобы он был здоров и счастлив.
Я желаю ему оставаться собой.
4. Пишешь стихи, песни, что-то, посвященное ему?
Да! Каждое мгновение описываю в строчках…
Пишу иногда всякий бред… =)
Нет, это не мое
5. Что ты чувствуешь, когда видишь, что он смотрит на тебя?
Это трудно описать. Адреналин, бешеное биение сердца, страх, счастье – мне очень хочется улыбаться, не знаю, почему. Даже сейчас мурашки по коже.
Я очень счастлива, мне как то не по себе…
Он не смотрит на меня!
6. Допустим (не принимай в прямом смысле, это просто пример. Может он и не умеет играть) он играет на фортепиано в Актовом зале. Ты решила подойти и послушать. И вот, ты стоишь… Он так близко…
Ты решила подойти и послушать. И вот, ты стоишь… Он так близко…
Черт! Я чувствую, что заливаюсь ярко-алой краской. Мне душно, жарко. Дышать почему-то трудно. Даже очень. Сердце бьется так сильно, кажется, оно выпрыгнет из груди. Я очень боюсь, что он услышит стук! Мне страшно…
Как он красиво играет… Слежу за движением его пальцев… Погружаюсь в мысли.
О Господи, он играет на фортепиано?!
7. Вот еще один пример. Не дай Бог такое случиться, тьфу-тьфу-тьфу. Допустим, он ужасно болен. Лежит в больнице. Я не знаю, что именно с ним случилось. Но, возможно, он скоро умрет.
Я приду к нему в больницу и проведу все время рядом с ним, не отходя от кровати. Я скажу ему, что любила его всем сердцем и люблю до сих пор. И буду любить. Каждый день я буду молиться о его выздоровлении… О нет, я не брошу его.
Черт… Я приду в больницу… Но ведь я не виновата в том. что с ним случилось… Я должна идти дальше, жизнь продолжается.
что с ним случилось… Я должна идти дальше, жизнь продолжается.
А мне все равно, мало ли кого я еще встречу.
8. Он рядом. Главное…
Не смотреть ему в глаза. Он поймет, что я люблю его. И не говорить лишнего. Смеяться попусту. Главное – утихомирить сердце, слишком уж бешено оно стучит.
Произвести положительное впечатление.
Найти нормальную тему для разговора… А лучше – побольше молчать…
9. Как поживает твой аппетит и сон?
В последнее время я мало ем и плохо сплю. Часто просыпаюсь ночью и долго не могу заснуть. Есть не хочется. Все время думаю о нем.
Хорошо. Я нормально сплю и ем. Иногда пропадает аппетит, и спится не очень, но редко.
О, мама приготовила пирог! СЪЕСТЬ ВСЕ! А потом и поспать немного…
10. Думаешь, ты любишь его по-настоящему?
Я ради него готова на все. Я люблю его так, как никто никогда не любил.
Я люблю его так, как никто никогда не любил.
Я люблю его… Но не думаю, что так бешено, как написано в нескольких ответах!)
Я думаю, он мне просто довольно нравится.
Разработка статистической викторины «Какой персонаж»
Эта страница служит руководством для статистической викторины «Какой персонаж» , а также для версии отчета коллег и пары.
Эта страница находится в разработке! Пожалуйста, зайдите как-нибудь для полированной версии!
Предыстория
Когда я, ваш автор, рассказывал людям, что я публикую личностные тесты в Интернете, меня часто спрашивали, означает ли это, что я работал на веб-сайт BuzzFeed, пишу их «Какой вы _________ персонаж?» викторины личности. И я должен был бы ответить, что нет, я больше интересуюсь наукой и человеческой природой, чем развлечением; эти викторины забавны, но не настолько значимы. И это не критика BuzzFeed! Ценность BuzzFeed (и всех других источников тестирования персонажей) подтверждается их популярностью. Это веселые игры. Людям нравится их принимать: дело закрыто. Однако, если вас интересует вопрос о том, как проводить хорошие психологические измерения, я полагаю, что они никогда не предлагали много интересного для размышлений. Я создал этот тест в 2019 году после того, как у меня появилась идея представить каждый символ в виде вектора, который можно заполнить краудсорсинговыми данными. И это на самом деле дало мне много интересных вещей для размышлений! Поэтому я немного отказываюсь от своего прежнего предубеждения против идеи характерной личности.
Это веселые игры. Людям нравится их принимать: дело закрыто. Однако, если вас интересует вопрос о том, как проводить хорошие психологические измерения, я полагаю, что они никогда не предлагали много интересного для размышлений. Я создал этот тест в 2019 году после того, как у меня появилась идея представить каждый символ в виде вектора, который можно заполнить краудсорсинговыми данными. И это на самом деле дало мне много интересных вещей для размышлений! Поэтому я немного отказываюсь от своего прежнего предубеждения против идеи характерной личности.
Дополнительной целью этого проекта было создание набора данных, который можно было бы использовать в статистических исследованиях и образовании. Я думаю, что этот набор данных отлично подходит для обучения факторному анализу или алгоритмам кластеризации. Из-за этой дополнительной цели набор данных был разработан так, чтобы он был намного богаче, чем это было бы необходимо только для создания теста. Например, количество функций, по которым пользователи оценивают персонажей, намного больше и разнообразнее.
Сбор рейтингов персонажей
Вместо того, чтобы создатель теста решал, каким должен быть профиль каждого персонажа, основываясь только на их мнении, мнения большого количества людей будут усредняться для создания профилей персонажей.
Был выбран формат 100-балльной шкалы, которая закреплена на каждом конце прилагательным.
Для начала тестовый набор данных был заполнен добровольцами из Reddit (начиная с персонажей «Игры престолов» и «Гарри Поттера»), но как только работоспособная версия теста была запущена, база данных стала самоподдерживающейся благодаря добровольцам, набранным из людей, принимавших участие в тестировании. тест. После того, как пользователь ответил на опрос личностного рейтинга, но до того, как он просмотрел свои результаты, его спрашивают, не хотят ли они оценить некоторых персонажей. Уровень отказа составляет около 35%. Затем добровольцев просят выбрать любые вымышленные вселенные, о которых они знают, из списка, а затем персонажи из этой вселенной сопоставляются с элементами из набора функций (обычно случайным образом), и они оценивают их. После этого задается еще несколько вопросов об отношении пользователя к этой вымышленной вселенной и некоторые демографические вопросы. Их опрос, где оценивались персонажи, менялся со временем, но в основном выглядел так, как показано на скриншоте ниже.
После этого задается еще несколько вопросов об отношении пользователя к этой вымышленной вселенной и некоторые демографические вопросы. Их опрос, где оценивались персонажи, менялся со временем, но в основном выглядел так, как показано на скриншоте ниже.
Шкала идет от 1 (крайний левый) до 100 (крайний правый). Пользователь не получил инструкций по этому поводу в рейтинговом опросе, но во время основной части теста они использовали аналогичные шкалы ползунков для оценки себя, которые отображали числовые значения, и поэтому пользователь должен был установить связь и понять, что шкала была. Количество оценок, которые дал бы конкретный пользователь, менялось с течением времени. Первоначально пользователям было назначено 30 оценок, но это оказалось слишком много, поэтому в настоящее время пользователям назначено 15 оценок, если только для вселенной, где данные редки, им назначено 25.
После этого было задано несколько вопросов, которые должны помочь оценить отношение этого пользователя к работе, как показано ниже.
Затем, наконец, были заданы некоторые демографические вопросы, чтобы представить выборку в контексте, изображенном ниже.
Это была последняя страница опроса волонтеров, и после ее отправки пользователи сразу же получали результаты. Эта страница также собирала согласие на использование данных пользователя в качестве последнего вопроса. Данные пользователей, которые не ответят утвердительно на этот вопрос, удаляются.
С помощью этой процедуры было собрано очень большое количество рейтингов. На приведенном ниже графике показано количество завершенных опросов в день с момента преобразования этого опроса в текущий рабочий процесс.
С учетом того, что каждый пользователь поставил до 30 оценок в одном опросе, в общей сложности было сделано более 69 496 000 оценок, распределенных по 400 элементам для 1750 символов. Они были распределены несколько неравномерно, так как более известные вселенные получают больше оценок, но были приняты меры, чтобы каждый элемент для каждого персонажа в базе данных получил не менее 3.
Генерация биполярных шкал
Формат элемента для викторины и набора данных был выбран в виде шкалы от 1 до 100 с закрепленным текстом на обоих концах. Это не самый распространенный формат в психологических измерениях, на самом деле рейтинговые шкалы с ползунками имеют существенные проблемы, за которые я ранее их критиковал. Причина, по которой был выбран этот формат, связана с соображениями пользовательского опыта. Чтобы сделать работу викторины понятной для пользователей, на странице результатов должен быть график, а график лучше выглядит с высокой степенью детализации. Например, если бы ответы пользователей оценивались по шкале от 1 до 5, составленная из них точечная диаграмма выглядела бы очень неуклюжей.
Элементы были созданы вашим автором с течением времени, пока их не стало 400. Это гораздо больше элементов, чем реально может быть использовано в викторине. Тест из 400 вопросов был бы слишком длинным. Но наличие всех этих элементов позволяет нам оценивать и выбирать наиболее эффективные элементы. Это также делает набор данных более полезным для образовательных целей.
Это также делает набор данных более полезным для образовательных целей.
Один из способов оценить, насколько хорош предмет, насколько он хорош. И этот метод более или менее похож на то, как делаются другие тесты персонажей: создатель задает вопросы, которые им кажутся хорошими. Как объяснялось ранее, суждение многих лучше, чем суждение одного. Итак, эта проблема была краудсорсингом для тестирования пользователей в опросе, который выглядел следующим образом.
Этот опрос проводился до тех пор, пока не менее 500 человек не высказали свое мнение по каждому вопросу. Ниже приведены вопросы с наивысшим и наименьшим средним баллом (4 = определенно включены; 1 = определенно исключены).
Проверка достоверности оценок пользователей
Предпосылка этой викторины заключается в том, что объединение оценок различных пользователей повышает их точность, но это предположение, которое не может быть верным. Например, если личность персонажа полностью находится в глазах смотрящего и не имеет согласованности между разными оценщиками, то идея любого теста на определение личности персонажа бессмысленна. Этот вопрос известен как межэтническая надежность. Говорить о характере определенного типа будет иметь смысл только в том случае, если люди согласны с тем, что персонаж именно такой. Обычно это измеряется коэффициентом внутриклассовой корреляции (ICC1). Значение ICC варьируется от 0 до 1. Где 0 означает отсутствие согласия, а 1 — полное согласие. В таблице ниже представлены 10 вопросов с самой высокой и самой низкой межоценочной надежностью.
Этот вопрос известен как межэтническая надежность. Говорить о характере определенного типа будет иметь смысл только в том случае, если люди согласны с тем, что персонаж именно такой. Обычно это измеряется коэффициентом внутриклассовой корреляции (ICC1). Значение ICC варьируется от 0 до 1. Где 0 означает отсутствие согласия, а 1 — полное согласие. В таблице ниже представлены 10 вопросов с самой высокой и самой низкой межоценочной надежностью.
Некоторые вопросы были более надежными, чем другие. Некоторые вопросы имели очень низкую надежность, и, глядя на них, это имеет смысл. Все элементы с низкой надежностью кажутся немного запутанными. Вопрос, который показал самую низкую надежность, — это контраст между «правополушарным» и «левополушарным». Этот вопрос является отсылкой к поп-психологической идее личности о том, что люди предпочитают использовать одну сторону своего мозга и что каждая сторона имеет определенные функции. Низкая согласованность оценок по этому вопросу совпадает с моим предыдущим опытом работы с этой идеей. В свое время я попытался создать свою собственную меру левополушарного мозга по сравнению с правым полушарием и обнаружил, что это была в основном бессвязная/бессмысленная идея. Каждое определение того, что, по их мнению, значит быть левым или правым полушарием, слишком сильно различалось, чтобы вообще быть полезным. См. раздел «Разработка шкалы доминирования открытого полушария мозга».
В свое время я попытался создать свою собственную меру левополушарного мозга по сравнению с правым полушарием и обнаружил, что это была в основном бессвязная/бессмысленная идея. Каждое определение того, что, по их мнению, значит быть левым или правым полушарием, слишком сильно различалось, чтобы вообще быть полезным. См. раздел «Разработка шкалы доминирования открытого полушария мозга».
Мы можем построить график зависимости надежности каждого вопроса от средней оценки вопроса, полученного в опросе, где пользователей спрашивали, какие вопросы, по их мнению, следует использовать в викторине. Некоторые точки были помечены, чтобы помочь с интерпретацией.
Корреляция между ними была положительной, но умеренной (r=0,37). Глядя на отдельные точки, мы можем понять, почему это имеет смысл. Пользователи, как правило, могли сказать, какие вопросы бессмысленны, и соглашались, что их не следует использовать в тесте. Некоторые вопросы были исключениями, когда они были надежными, но по-прежнему получали низкое одобрение пользователей. Одним из них был пункт молодой (не старый) . Это второй самый надежный вопрос, но он получил очень низкие оценки пользователей. И в этом есть смысл, пользователи не любят этот вопрос, потому что он бессмысленный, они не любят его, потому что он не о личности. Итак, вы можете видеть, как это демонстрирует, что важно, чтобы вопрос был надежным, но надежности недостаточно.
Одним из них был пункт молодой (не старый) . Это второй самый надежный вопрос, но он получил очень низкие оценки пользователей. И в этом есть смысл, пользователи не любят этот вопрос, потому что он бессмысленный, они не любят его, потому что он не о личности. Итак, вы можете видеть, как это демонстрирует, что важно, чтобы вопрос был надежным, но надежности недостаточно.
Причины ненадежности
Моделирование рейтингов личности персонажа
Итак, у нас есть все эти рейтинги персонажей, и мы можем спросить: «Какая модель личности персонажа является лучшей?» Набор данных содержит 400 значений для каждого символа, но, возможно, некоторые из этих значений избыточны? Вероятно, вы могли бы хорошо описать символы с гораздо менее чем 400 значениями на символ. Типичный анализ для этого в психометрии называется факторным анализом. Факторный анализ пытается объяснить больший набор наблюдаемых значений меньшим набором фундаментальных причин.
Когда вы запускаете факторный анализ, первое, на что вы смотрите, это «график осыпи». Факторный анализ извлекает факторы по одному, каждый раз пытаясь заставить извлеченный фактор выполнять как можно больше работы, поэтому каждый последующий фактор выполняет меньше работы, чем предыдущий. Вы можете посмотреть, какую дисперсию объясняет каждый фактор, а затем сделать вывод о том, насколько они важны. График осыпи, полученный в результате факторного анализа 400 значений для 1600 символов, приведен ниже.
Факторный анализ извлекает факторы по одному, каждый раз пытаясь заставить извлеченный фактор выполнять как можно больше работы, поэтому каждый последующий фактор выполняет меньше работы, чем предыдущий. Вы можете посмотреть, какую дисперсию объясняет каждый фактор, а затем сделать вывод о том, насколько они важны. График осыпи, полученный в результате факторного анализа 400 значений для 1600 символов, приведен ниже.
Интерпретация сюжета осыпи — это больше искусство, чем наука, но я хочу сказать, что вижу 8 факторов, которые, похоже, работают здесь. Поэтому для остальной части анализа в этом разделе я буду рассматривать только первые 8 извлеченных факторов. Факторный анализ вычисляет нагрузку каждой переменной на каждый фактор. Нагрузка — это то, как анализ оценивает корреляцию этой переменной с фактором. Таким образом, мы можем посмотреть на переменные с наибольшей нагрузкой, чтобы попытаться интерпретировать, что представляет собой каждый фактор. В приведенной ниже таблице показаны нагрузки нескольких основных элементов, которые нагружают каждый фактор.
| Feature | Factor loading | |||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |||
| cruel (not kind) | 0.97 | -0,01 | 0,07 | 0,06 | 0,01 | -0,01 | 0,03 | -0,01 | ||
| Яреоли0071 | 0.05 | 0.02 | -0.01 | 0.07 | 0.02 | |||||
| angelic (not demonic) | -0.95 | -0.17 | -0.09 | 0.02 | 0 | 0.01 | -0.05 | -0.02 | ||
| scheduled (not spontaneous) | 0.04 | -0.92 | 0.04 | 0.17 | -0.17 | 0.04 | 0 | 0.02 | ||
| serious (not bold) | 0.01 | -0.9 | -0.07 | -0. 02 02 | -0.09 | -0.06 | 0.24 | 0 | ||
| orderly (not chaotic) | -0.28 | -0.87 | 0.18 | 0.21 | -0.06 | -0.05 | -0.05 | 0.01 | ||
| noob (not pro) | 0.05 | 0.08 | -0.9 | -0.04 | 0.06 | 0 | -0.02 | -0.08 | ||
| mighty (not puny) | -0.06 | -0.02 | 0.9 | 0.01 | 0.19 | 0.03 | 0.07 | -0.08 | ||
| badass (not weakass) | -0.15 | 0.15 | 0.89 | -0.07 | 0.09 | 0.03 | 0.04 | -0.01 | ||
| scruffy (not manicured) | 0.02 | 0.31 | -0.04 | -0.86 | 0.04 | -0.07 | 0.12 | -0.01 | ||
| blue-collar (not ivory-tower) | -0. 31 31 | 0.05 | 0.01 | -0.83 | 0.16 | 0 | -0.02 | -0.03 | ||
| proletariat (not bourgeoisie) | -0.4 | 0.09 | 0.05 | -0.82 | 0.02 | 0 | 0.05 | 0.02 | ||
| sporty (not bookish) | 0.13 | 0.36 | 0.18 | -0.21 | 0.84 | -0.02 | -0.04 | -0.03 | ||
| nerd (not jock ) | -0.27 | -0.22 | -0.3 | 0.06 | -0.8 | 0.07 | -0.02 | 0.15 | ||
| intellectual (not physical) | -0.14 | -0.39 | 0.1 | 0.27 | -0.79 | 0 | 0.03 | 0.14 | ||
| leisurely (not hurried) | -0.07 | 0.45 | 0 | 0.01 | -0.01 | -0. 77 77 | -0.18 | -0.1 | ||
| sleepy (not frenzied) | -0.29 | -0.24 | -0.25 | -0.16 | -0.02 | -0.74 | 0.1 | -0.04 | ||
| aloof (not obsessed) | -0.38 | 0.1 | -0.04 | -0.11 | 0.16 | -0.67 | -0.08 | -0.08 | ||
| sad (not happy) | 0.53 | -0.23 | 0 | -0.1 | -0.04 | 0.05 | 0.76 | -0.01 | ||
| cheery (not sorrowful) | -0.48 | 0.36 | -0.12 | 0.15 | 0.02 | -0.01 | -0.73 | 0.01 | ||
| traumatized (not flourishing) | 0.38 | -0.02 | -0.26 | -0.26 | 0 | 0.16 | 0.68 | 0.02 | ||
| luddite (not technophile) | 0. 09 09 | 0.04 | -0.07 | -0.19 | 0.18 | -0.06 | 0 | -0.91 | ||
| high-tech (not or low-tech ) | -0,02 | -0,07 | 0,23 | 0,29 | -0,19 | 0,1 | 0,01 | 0,86 | 0,01 | 0,86 | 0,01 |
 В некотором смысле это будет похоже на рекомендательный механизм, который рекомендует пользователям персонажей, и критерий хороших результатов заключается в том, что пользователь соглашается с тем, что рекомендуемые персонажи похожи на них.
В некотором смысле это будет похоже на рекомендательный механизм, который рекомендует пользователям персонажей, и критерий хороших результатов заключается в том, что пользователь соглашается с тем, что рекомендуемые персонажи похожи на них.
 Давайте исследуем один выброс на графике:
Давайте исследуем один выброс на графике: увеличило бы корреляцию, но мое предположение, вероятно, не так уж сильно (в среднем я ожидаю, что IMDb будет довольно точным). Таким образом, у нас все еще есть вопрос, почему корреляция не r = 1 при поправке на ненадежность? этого теста, что, если мы усредним оценки людей, мы получим «истинную оценку»?0005
увеличило бы корреляцию, но мое предположение, вероятно, не так уж сильно (в среднем я ожидаю, что IMDb будет довольно точным). Таким образом, у нас все еще есть вопрос, почему корреляция не r = 1 при поправке на ненадежность? этого теста, что, если мы усредним оценки людей, мы получим «истинную оценку»?0005 В этом есть интуитивный смысл, и вы, вероятно, можете распознать это в своем собственном мышлении: женщина ростом 6 футов очень высока для женщины, поэтому вы можете заметить, насколько она высока, но мужчина ростом 6 футов не особенно высок для мужчины. . Если вы контролируете пол актера / персонажа, корреляция между ростом актера и номинальным ростом персонажа увеличивается с r = 0,693 до r = 0,749..
В этом есть интуитивный смысл, и вы, вероятно, можете распознать это в своем собственном мышлении: женщина ростом 6 футов очень высока для женщины, поэтому вы можете заметить, насколько она высока, но мужчина ростом 6 футов не особенно высок для мужчины. . Если вы контролируете пол актера / персонажа, корреляция между ростом актера и номинальным ростом персонажа увеличивается с r = 0,693 до r = 0,749.. Вместо психологической оценки давайте попробуем осмыслить то, что мы делаем, как механизм рекомендаций с целью максимальной идентификации пользователя. Основным инструментом, используемым здесь, является вопрос, показанный ниже:
Вместо психологической оценки давайте попробуем осмыслить то, что мы делаем, как механизм рекомендаций с целью максимальной идентификации пользователя. Основным инструментом, используемым здесь, является вопрос, показанный ниже: Чтобы получить эту оценку, вычисляется корреляция между средними оценками для каждого персонажа и самооценкой, предоставленной пользователем. Эта корреляция находится в диапазоне от -1 до 1, поэтому, чтобы превратить ее в процент, к этому числу добавляется 1 и умножается на 50. Алгоритм средней разницы берет среднюю разницу между оценкой пользователя и оценкой персонажей и вычитает ее из 100. Баллы в версиях теста с большим количеством вопросов, как правило, ниже для наиболее подходящего символа, чем в версиях с меньшим количеством вопросов. Чем больше у вас критериев, тем сложнее найти идеальное соответствие.
Чтобы получить эту оценку, вычисляется корреляция между средними оценками для каждого персонажа и самооценкой, предоставленной пользователем. Эта корреляция находится в диапазоне от -1 до 1, поэтому, чтобы превратить ее в процент, к этому числу добавляется 1 и умножается на 50. Алгоритм средней разницы берет среднюю разницу между оценкой пользователя и оценкой персонажей и вычитает ее из 100. Баллы в версиях теста с большим количеством вопросов, как правило, ниже для наиболее подходящего символа, чем в версиях с меньшим количеством вопросов. Чем больше у вас критериев, тем сложнее найти идеальное соответствие. Но есть один альтернативный метод сопоставления людей с персонажами, с которыми мы можем провести детальное сравнение: типы личности Майерс-Бриггс. Майерс-Бриггс, или Юнгианский тип, представляет собой систему из 16 типов личности. Это самая популярная система в Интернете, и одним из ее распространенных применений является ввод вымышленных персонажей. Обычный формат заключается в том, что кто-то составляет таблицу персонажей из вымышленной вселенной и выбирает по одному примеру, который, по его мнению, подходит для каждого из 16 типов. Обычно это выглядит как мем ниже, который показывает набор символов «Звездных войн» (от Entertainment Earth News):
Но есть один альтернативный метод сопоставления людей с персонажами, с которыми мы можем провести детальное сравнение: типы личности Майерс-Бриггс. Майерс-Бриггс, или Юнгианский тип, представляет собой систему из 16 типов личности. Это самая популярная система в Интернете, и одним из ее распространенных применений является ввод вымышленных персонажей. Обычный формат заключается в том, что кто-то составляет таблицу персонажей из вымышленной вселенной и выбирает по одному примеру, который, по его мнению, подходит для каждого из 16 типов. Обычно это выглядит как мем ниже, который показывает набор символов «Звездных войн» (от Entertainment Earth News): Пользователи оценивают персонажей по типам личности Майерс-Бриггс и Эннеаграммы, и все это объединяется в вердикт сообщества. PDB является самым популярным веб-сайтом для набора текста сообществом Майерс-Бриггс, и его вердикты будут использоваться в этом анализе в качестве ключа для того, к какому типу относится каждый символ в системе Майерс-Бриггс. Из 1600 профилей символов в наборе данных SWCPQ1.0 1537 имеют совпадающие профили в PDB.
Пользователи оценивают персонажей по типам личности Майерс-Бриггс и Эннеаграммы, и все это объединяется в вердикт сообщества. PDB является самым популярным веб-сайтом для набора текста сообществом Майерс-Бриггс, и его вердикты будут использоваться в этом анализе в качестве ключа для того, к какому типу относится каждый символ в системе Майерс-Бриггс. Из 1600 профилей символов в наборе данных SWCPQ1.0 1537 имеют совпадающие профили в PDB. Для каждого из них у нас есть много тысяч человек, которые и сами сообщили о типе Майерс-Бриггс, и оценили, насколько они похожи на персонажа. На приведенных ниже графиках показано, какой процент каждого типа Майерс-Бриггс дал каждому различную оценку сходства с ними.
Для каждого из них у нас есть много тысяч человек, которые и сами сообщили о типе Майерс-Бриггс, и оценили, насколько они похожи на персонажа. На приведенных ниже графиках показано, какой процент каждого типа Майерс-Бриггс дал каждому различную оценку сходства с ними. Они спрашивают, насколько полезны эти прилагательные, какую работу они выполняют?
Они спрашивают, насколько полезны эти прилагательные, какую работу они выполняют?
 Это означает, что они не очень хорошо передают информацию о добре и зле. А добро и зло — это самое главное, на чем люди основывают свои суждения о том, насколько персонаж похож на них. Учитывая, что сопоставление характеров не было целью, для которой разрабатывались типы личности Майерс-Бриггс, тот факт, что они плохо справляются с этой задачей, на самом деле не опровергает идею 16 типов напрямую. Но многие люди в Интернете предположили, что поиск персонажей того же типа, что и у вас, имеет большое значение. Я бы указал на это как на еще один пример распространенного явления, когда люди сильно переоценивают полезность категоризации по типам Майерс-Бриггс.
Это означает, что они не очень хорошо передают информацию о добре и зле. А добро и зло — это самое главное, на чем люди основывают свои суждения о том, насколько персонаж похож на них. Учитывая, что сопоставление характеров не было целью, для которой разрабатывались типы личности Майерс-Бриггс, тот факт, что они плохо справляются с этой задачей, на самом деле не опровергает идею 16 типов напрямую. Но многие люди в Интернете предположили, что поиск персонажей того же типа, что и у вас, имеет большое значение. Я бы указал на это как на еще один пример распространенного явления, когда люди сильно переоценивают полезность категоризации по типам Майерс-Бриггс. Какая бы викторина ни поставила персонажа, которого они претендовали на более высокое место на странице результатов (после исправления общего количества вариантов), считалась победителем этого совпадения. В общей сложности участвовало 15 реддиторов, и результаты были представлены как «11 побед для OpenPsychometrics и 4 победы для CharacTour» (см. ветку на r/SampleSize). Это говорит о том, что викторина на этом веб-сайте имеет лучшую процедуру сопоставления, хотя n = 15 слишком мало для меня, чтобы делать какие-либо супер конкретные заявления.
Какая бы викторина ни поставила персонажа, которого они претендовали на более высокое место на странице результатов (после исправления общего количества вариантов), считалась победителем этого совпадения. В общей сложности участвовало 15 реддиторов, и результаты были представлены как «11 побед для OpenPsychometrics и 4 победы для CharacTour» (см. ветку на r/SampleSize). Это говорит о том, что викторина на этом веб-сайте имеет лучшую процедуру сопоставления, хотя n = 15 слишком мало для меня, чтобы делать какие-либо супер конкретные заявления. Хотите…? = ‘Хочешь…?’
Хотите…? = ‘Хочешь…?’ (=Я думаю, что кофе хорош.)
(=Я думаю, что кофе хорош.)