Пример речевых ошибок: что это такое и как с ними бороться

Речевые ошибки – проблема тысячелетия
В латыни есть слово lapsus. Оно обозначает ошибку в речи человека. От этого слова появилось всем известное сокращение ляп. Только если ляп считают грубым нарушением норм речи, то lapsus имеет не настолько строгое значение. К сожалению, аналога этого слова, которое обозначает речевые ошибки, в современном русском языке нет. Но lapsus встречаются повсеместно.
Содержание
- Типы речевых ошибок
- Виды нормативных ошибок
- Орфоэпическая ошибка
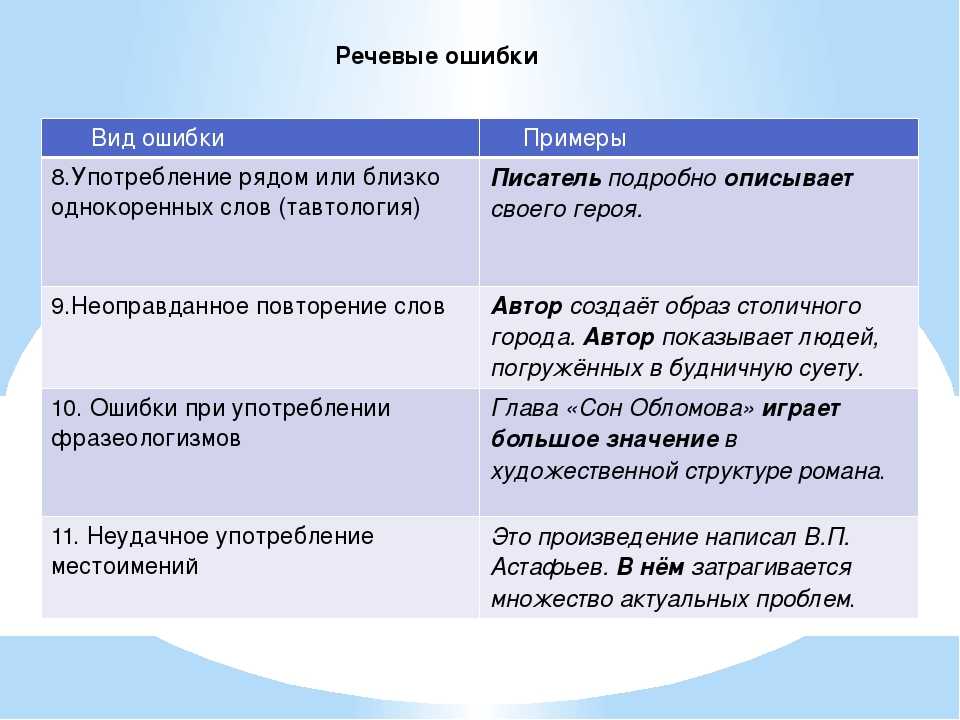
- Морфологическая ошибка
- Орфографическая ошибка
- Синтаксически-пунктуационные ошибки
- Стилистические ошибки
- Лексические речевые ошибки
Типы речевых ошибок
Речевые ошибки подразделяются на нормативные ошибки и опечатки. Опечатками называют механические ошибки. В тексте слово может быть написано неверно, что усложнит восприятие информации. Или же вместо одного слова случайно используют другое. Опечатки встречаются и в устной речи. Это оговорки, которые можно услышать от людей каждый день.
Это оговорки, которые можно услышать от людей каждый день.
Механические ошибки происходят неосознанно, но от них многое зависит. Ошибки в написании цифр создают искажение фактической информации. А неправильное написание слов может полностью изменить смысл сказанного. Хорошо демонстрирует проблему опечаток одна сцена из фильма «Александр и ужасный, кошмарный, нехороший, очень плохой день» режиссера Мигеля Артета. В типографии перепутали буквы «п» и «с» и в детской книжке написали вместо «Можно прыгнуть на кровать» фразу «Можно срыгнуть на кровать». И по сюжету кинокартины эта ситуация вылилась в скандал.
Особое внимание уделяли опечаткам во времена сталинских репрессий, когда неверно написанное слово стоило человеку жизни. Искоренить проблему опечаток, невозможно, так как человек делает их неосознанно. Единственный способ, при помощи которого вы избежите этого типа речевых ошибок, быть внимательным при написании текста, тщательно подбирать слова, которые вы произнесете.

Виды нормативных ошибок
Речевые ошибки связаны с нарушением норм русского языка. Виды речевых ошибок:
- орфоэпические;
- морфологические;
- орфографические;
- синтаксически-пунктуационные;
- стилистические;
- лексические.
Орфоэпическая ошибка
Произносительная ошибка связана с нарушением норм орфоэпии. Она проявляется только в устной речи. Это ошибочное произношение звуков, слов или же словосочетаний. Также к ошибкам в произношении относят неправильное ударение.
Искажение слов происходит в сторону сокращения количества букв. К примеру, когда вместо «тысяча» произносится слово «тыща». Если вы хотите говорить грамотно и красиво, стоит избавить речь от подобных слов. Распространено также ошибочное произношение слова «конечно» — «конешно».
Произносить правильное ударение не только правильно, но и модно. Наверняка вы слышали, как люди поправляют неправильное ударение в словах «Алкоголь», «звОнит», «дОговор» на верные – «алкогОль», «звонИт» и «договОр». Неправильная постановка ударения в последнее время заметнее, чем раньше. И мнение о вашей эрудиции зависит от соблюдения норм произношения.
Неправильная постановка ударения в последнее время заметнее, чем раньше. И мнение о вашей эрудиции зависит от соблюдения норм произношения.
Морфологическая ошибка
Морфологией называют раздел лингвистики, в котором объектом изучения являются слова и их части. Морфологические ошибки получаются из-за неправильного образования форм слов различных частей речи. Причинами являются неправильное склонение, ошибки в употреблении рода и числа.
К примеру, «докторы» вместо «доктора». Это морфологическая ошибка в употреблении множественного числа.
Часто употребляют неверную форму слова при изменении падежа. Родительный падеж слова яблоки – яблок. Иногда вместо этого слова употребляют неверную форму «яблоков».
Распространенные морфологические ошибки – неверное написание числительных:
«Компания владела пятьюстами пятьдесят тремя филиалами». В этом примере слово «пятьдесят» не склонили. Верное написание: «Компания владела пятьюстами пятьюдесятью тремя филиалами».
В употреблении прилагательных распространена ошибка неверного употребления сравнительной степени. К примеру, такое использование: «более красивее» вместо «более красивый». Или же «самый высочайший» вместо «самого высокого» или «высочайшего».
Орфографическая ошибка
Орфографические ошибки – это неправильное написание слов. Они возникают тогда, когда человек не знает правильного написания слова. Вы получали когда-либо сообщение, где находили грамматические ошибки. Распространенный пример: написание слова «извини» через «е». Чтобы с вами не случалось подобных орфографических ошибок, как можно больше читайте. Чтение стимулирует восприятие правильного написания слов. И если вы привыкли читать правильно написанный текст, то и писать вы будете, не делая грамматические ошибки.
Орфографические ошибки, в принципе, случаются из-за незнания правильности слов. Поэтому если вы не уверены в написанном слове, стоит обратиться к словарю. На работе узнавайте тот перечень специфических для вашей области слов, который нужно запомнить и в котором ни в коем случае нельзя совершать грамматические ошибки.

Синтаксически-пунктуационные ошибки
Эти виды речевых ошибок возникают при неправильной постановке знаков препинания и неверном соединении слов в словосочетаниях и предложениях.
Пропуск тире, лишние запятые – это относится к ошибкам пунктуации. Не поленитесь открыть учебник, если вы не уверены в постановке запятой. Опять же, это та проблема, с которой можно справиться, читая много книг. Вы привыкаете к правильной постановке знаков препинания и уже на интуитивном уровне вам сложно совершить ошибку.
Нарушение правил синтаксиса встречается часто. Распространены ошибки в согласовании. «Человеку для счастья нужно любимое место для отдыха, работа, счастливая семья». Слово «нужно» в этом предложении не подходит при перечислении. Необходимо употребить «нужны».
Профессиональные редакторы считают, что часто встречается ошибка в управлении. Когда слово заменяется на синоним или же похожее слово, но управление с новым словом не согласуется.
Пример ошибки в управлении: «Они хвалили и приносили поздравления Алине за победу».
Они хвалили Алину. Они приносили поздравления Алине. Части предложения не согласуются из-за неправильного управления. После «хвалили» необходимо добавить слово «ее», чтобы исправить ошибку.
Стилистические ошибки
В отличие от других видов ошибок, стилистические основываются на искажении смысла текста. Классификация основных стилистических речевых ошибок:
- Плеоназм. Явление встречается часто. Плеоназм — это избыточное выражение. Автор выражает мысль, дополняя ее и так всем понятными сведениями. К примеру, «прошла минута времени», «он сказал истинную правду», «за пассажиром следил секретный шпион». Минута – это единица времени. Правда – это истина. А шпион в любом случае является секретным агентом.
- Клише. Это устоявшиеся словосочетания, которые очень часто используются. Клише нельзя полностью отнести к речевым ошибкам. Иногда их употребление уместно. Но если они часто встречаются в тексте или же клише разговорного стиля используется в деловом – это серьезная речевая ошибка.
 К клише относят выражения «одержать победу», «золотая осень», «подавляющее большинство».
К клише относят выражения «одержать победу», «золотая осень», «подавляющее большинство». - Тавтология. Ошибка, в которой часто повторяются одни и те же либо однокоренные слова. В одном предложении одно и тоже слово не должно повторяться. Желательно исключить повторения в смежных предложениях.
Предложения, в которых допущена эта ошибка: «Он улыбнулся, его улыбка наполнила помещение светом», «Катя покраснела от красного вина», «Петя любил ходить на рыбалку и ловить рыбу».
- Нарушение порядка слов. В английском языке порядок слов намного строже, чем в русском. Он отличается четким построением частей предложения в определенной последовательности. В русском языке можно менять местами словосочетания так, как вам бы хотелось. Но при этом важно не потерять смысл высказывания.
Для того, чтобы этого не случилось, руководствуйтесь двумя правилами:
- Порядок слов в предложении может быть прямым и обратным в зависимости от подлежащего и сказуемого.

- Второстепенные члены предложения должны согласоваться с теми словами, от которых они зависят.
Лексические речевые ошибки
Лексика – это словарный запас языка. Ошибки возникают тогда, когда вы пишите либо говорите о том, в чем не разбираетесь. Чаще ошибки в значениях слов происходят по нескольким причинам:
- Слово устарело и редко используется в современном русском языке.
- Слово относится к узкоспециализированной лексике.
- Слово является неологизмом и его значение не распространено.
Классификация лексических речевых ошибок:
- Ложная синонимия. Человек считает синонимами несколько слов, которые ими не являются. Например, авторитет не есть популярность, а особенности не являются различиями. Примеры, где допущена ошибка: «Певица была авторитетом среди молодежи» вместо «Певица была популярной среди молодежи». «У брата и сестры было много особенностей в характерах» вместо «У брата и сестры было много различий в характерах».

- Употребление похожих по звучанию слов. Например, употребление слова «одинарный», когда необходимо сказать «ординарный». Вместо слова «индианка» могут написать ошибочное «индейка».
- Путаница в близких по значению словах. «Интервьюер» и «Интервьюируемый», «Абонент» и «Абонемент», «Адресат» и «Адресант».
- Непреднамеренное образование новых слов.
Предыдущая статьяПредыдущаяСледующая статьяСледующая
Речевые ошибки русского языка — примеры типичных ошибок в речи
Граммар-наци – ваше второе имя? С одной стороны, это очень неэтично – строить из себя всезнайку и при личном общении, и в онлайн переписке в социальных сетях. Но с другой, это же невежество – быть безграмотным и не знать свой родной русский язык. У каждого есть подруга или друг, которые регулярно говорят «позвОнишь». Как же это режет слух, и вы с нескрываемым раздражением шпыняете ее за это. Но что, если попробовать в шутливой форме в ответ говорить «позвонИшь»? Это будет намного эффективней, и в один прекрасный момент вы услышите долгожданное правильное ударение!
Но что, если попробовать в шутливой форме в ответ говорить «позвонИшь»? Это будет намного эффективней, и в один прекрасный момент вы услышите долгожданное правильное ударение!
Примеры речевых ошибок в русском языке
Люди общаются при помощи речи, это своеобразный канал связи. А, как известно, при нарушении сигнала, связь может оборваться. Поэтому чтобы человеческие узы оставались неразрывными, речь должна быть правильной. Какие типичные ошибки бывают допущены в произношении имени собственного?
УкраИна или УкрАина?
Все производные названия страны должны произноситься с ударением на согласную И: УкраИна, житель ‒ украИнец, язык ‒ украИнский. Ошибочно делать ударение на букву А.
Мэрилин Монро за чтением
Просклоняем Марию Цигаль по падежам
— Кто, что?
— Мария Цигаль.
— Кого, чего?
— Марию Цигаль.
— Кому, чему?
— Марии Цигаль и т. д.
Женские фамилии, которые заканчиваются на мягкий знак, не склоняются.
В Иванове или в Иваново?
Как часто мы слышим: «Мы живем в Иванове» или «Мы живем в Иваново». Правильно – жить в городе Иваново, жить в Иванове.
Ниже приведены примеры типичных речевых ошибок в русском языке и особенность употребления этих слов.
Вовнутрь? ВНУТРЬ!
Одеваясь, мы заправляем кофточку ВНУТРЬ юбки. Открывая конверт, мы смотрим ВНУТРЬ. Никаких приставок «во» не должно быть.
Одеть? НАДЕТЬ!
Этот случай, пожалуй, самое распространенное неправильное употребление слова в речи. Существует простое правило, по которому легко запомнить правильное употребление этих слов в зависимости от контекста. НАДЕТЬ шляпу – ОДЕТЬ дочку. Когда дело касается вас самих, в этом случае НАдеть, кого-то другого – Одеть.
Мэрилин Монро внимательно читает книгу
Закончить школу, вуз? ОКОНЧИТЬ!
В школе задали сделать собственный проект. И вот дело ЗАкончено. Вы прибрались дома – ЗАкончили. Как вы поняли, заканчивают дело, а учебное заведение (вуз, школа, автокурсы) Оканчивают.
Как вы поняли, заканчивают дело, а учебное заведение (вуз, школа, автокурсы) Оканчивают.
Кипельно-белый? КИПЕННО-БЕЛЫЙ!
Вы варите макароны или мясо, а на поверхности всегда образуется белоснежная пена – кипень, так называли ее наши предки когда-то в давние времена.
Поэтому белые предметы гардероба кипенно-белые – и никакие другие!
Коллеги по работе? Просто КОЛЛЕГИ!
Слово «коллега» уже по умолчанию имеет следующее значение: «человек, который со мной вместе работает, или имеющий аналогичную профессию», поэтому пояснять, что «Вася – мой коллега по работе» – избыточное выражение.
Крема, свитера, джемпера? КРЕМЫ, СВИТЕРЫ, ДЖЕМПЕРЫ!
Окончание «а» в этих словах мы слышим регулярно, оно привносит в разговорную речь некой «простецкости». Намного более «поэтичнее» и правильнее использовать на конце «ы»: сегодня ходили по магазинам и купили теплые джемперы, а потом зашли в отдел косметики и купили питательные кремы.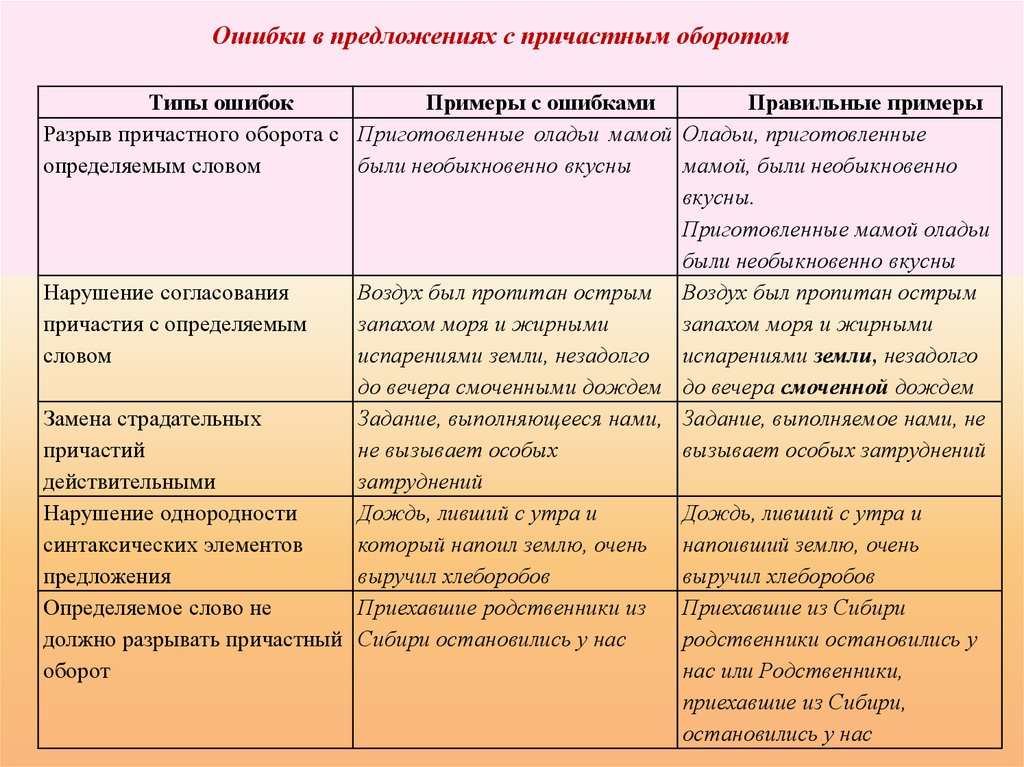
Кушать? ЕСТЬ!
Произнося фразу «я покушала», помните, что звучит она словно из уст манерной кокетки. Слово «есть» универсально. Стоит различать границы можно-нельзя. Спросить ребенка, кушал ли он, вполне этично. Однако взрослый мужчина, ответивший о себе: «я покушал» – это моветон.
Ложить? КЛАСТЬ!
Одной из самых распространенных ошибок в речи считается именно эта. Запомните правило: слова «ложить» не существует, оно употребляется только с приставками: ПОложить на стол, Сложи в стопку и т. д. Знаменитая фраза из фильмов: «положь трубку» тоже не является нормой. Только «положи, клади».
Навряд ли, напополам? ВРЯД ЛИ, ПОПОЛАМ!
Помните популярную в 90-х группу «На-на»? Так вот: в случае этих слов никакие «на-на» не нужны: ВРЯД ЛИ сегодня мы куда-нибудь пойдем, разделим фрукт ПОПОЛАМ.
Мэрилин Монро читает книгу в постели
По приезду, по прибытию, по окончанию? ПО ПРИЕЗДЕ, ПО ПРИБЫТИИ, ПО ОКОНЧАНИИ!
Правильное употребление этих слов в первую очередь возлагается на вашу зрительную память, частое чтение и интерес к словарям, так как проверочных правил к ним нет. Остается только хорошенько запомнить, зазубрить.
Остается только хорошенько запомнить, зазубрить.
Простынь? ПРОСТЫНЯ!
Как легко ошибиться с окончанием слов «нь, ня». Изыди разговорный вариант «простынь» из нашего лексикона! Для этого придется вспомнить детство и известное стихотворение Чуковского «Мойдодыр»:
«Одеяло убежало, улетела простыня, и подушка, как лягушка, ускакала от меня…»
Пылесошу? Пылесосю? ЧИЩУ ПЫЛЕСОСОМ!
Борьба за чистоту в доме часто заканчивается борьбой за правильную речь! Вы наводите порядок, но вдруг позвонила подруга и спрашивает, чем вы занимаетесь. Вы отвечаете: «пылесосю…пылесошу…сосу пыль»… Правильно – «чищу пылесосом»!
Согласно приказа, распоряжения? Согласно ПРИКАЗУ, РАСПОРЯЖЕНИЮ!
После предлога «согласно» всегда идет существительное в родительном падеже, то есть отвечающее на вопрос «чему»: «согласно чему? Приказу.» Премия за месяц выписана согласно приказу директора предприятия.
Стираться? СТИРАТЬ!
Употребляя в словах стирать, полоскать, убирать добавочное окончание «ся», вы как бы приписываете действие себе, то есть вы собрались себя любимую полоскать, стирать и оттирать от грязи.
Туфлей? ТУФЕЛЬ!
Нельзя не вспомнить знаменитую фразу из фильма «Кавказская пленница», ставшую чуть ли не крылатой: «Чей туфля». Слово «туфли» неизменно. Правильное употребление: сегодня меряла пару туфель, которая мне очень понравились.
Чаю, сахару или ЧАЯ, САХАРА?
Эксперты справочной службы русского языка «Грамоты.ру» отвечают: оба варианта допустимы. И добавляют: если раньше формы на -у, -ю (выпить чаю, съесть супу, добавить сахару) были предпочтительнее, то сейчас они приобрели разговорный оттенок и постепенно уступают свою популярность формам на -а, -я (налить чая, положить сахара).
Мэрилин Монро читает книгу, лёжа на кушетке
Экспрессо? ЭСПРЕССО!
А не пойти ли выпить чашечку любимого эКспрессо. Если вы это слышите, вы практически оскорблены до глубины души! Это самое распространенное неправильное употребление слова в речи. Причина путаницы – смешение двух слов из итальянского и английского языков, имеющие похожее звучание и одинаковое значение: espresso – быстрый по-итальянски, express – «быстрый, срочный, экстренный» по-английски. На эКспрессе мы поедем из Москвы в Питер, наслаждаясь чашечкой любимого эспрессо, сидя в вагоне-ресторане.
На эКспрессе мы поедем из Москвы в Питер, наслаждаясь чашечкой любимого эспрессо, сидя в вагоне-ресторане.
Какие виды распространенных ошибок в разговорной речи встречаются:
- Произносительные: плотит (неверно) – платит (верно), конешно (неверно) ‒ конечно (верно).
- Лексические: индианка – индейка.
- Фразеологические: объединение двух устойчивых фраз («спустя рукава» и «сложа руки») – «Нельзя это делать сложа рукава».
- Морфологические: полотенцев, пианинов, подешевше и др.
- Синтаксические: на столе лежат много книг (неправильное согласование).
- Орфографические: тубарет, вогзал, сдесь и т. д. (встречаются в письменной речи).
Смешные ошибки в словах
Частенько мы допускаем смешные ошибки в словах и даже не замечаем этого. Иногда это происходит случайно (оговорка), но чаще всего человек действительно не знает, как правильно произносится слово. Евошний, евонный, ихний – это так по-деревенски. Это неверные производные от слов «его» и «их». «Было бы смешно, если бы не было так грустно». Самые распространенные ошибки в русском языке часто делаются на автомате. Мы где-то услышали это слово, запомнив его на подсознательном уровне. Поэтому если вы не хотите случайно опозориться на каком-то выступлении на работе, на публике, тщательно «фильтруйте базар».
Это неверные производные от слов «его» и «их». «Было бы смешно, если бы не было так грустно». Самые распространенные ошибки в русском языке часто делаются на автомате. Мы где-то услышали это слово, запомнив его на подсознательном уровне. Поэтому если вы не хотите случайно опозориться на каком-то выступлении на работе, на публике, тщательно «фильтруйте базар».
«Этовать» – что за зверь такой?
Мало кто знает такое слово, как этовать. А оказывается оно существует. По значению его можно сравнить с английским Do, обозначающим действие, но неопределенное. Это универсальный глагол, которым можно заменить другой в зависимости от контекста.
– «Чем занималась сегодня?»
– «Да этовала весь день!»
или
– «Хватит тут этовать мне!»
Вот такой он, разнообразный русский язык, разные в нем и особенности употребления слов в речи. Некоторые слова, которые сейчас не употребляются, нередко принимают за речевые ошибки те, кто не знает их значение. Например: агнец – ягненок, град – город, черница – монахиня и др.
Шпаргалка! Проверить интересующее вас слово – его произношение, ударение, правописание, особенности значения и употребления – можно с помощью порталов «Грамота.ру», «Грамма.ру», «Яндекс-словари». Сайт «Орфограммка.ру» позволяет избавлять от ошибок целые предложения и абзацы – навести порядок, например, в тексте комментария, письма. Тренировать грамотность интересно, выполняя онлайн-диктанты (все слышали о проекте «Тотальный диктант»?) и интерактивные упражнения, которых много на «Грамоте.ру»
Примеры предложений с частыми речевыми ошибками постоянно на слуху:
- У меня не оплОчены счета.
- Нужно ложить вещи вот так.
- Ты позвОнишь мне?
Даже в СМИ нередко допускают подобное: «Благодаря землетрясению погибли тысячи жителей».
Заключение
Говорить на родном языке правильно – это не только обязанность гражданина страны, но и уважительное отношение его к другим членам общества. Именно поэтому так важно уже с детства прививать ребенку любовь к изучению языка. Неправильная косноязычная речь приводит к непониманию при общении между людьми.
Неправильная косноязычная речь приводит к непониманию при общении между людьми.
30 ошибок в письменной и устной речи, за которые должно быть стыдно
29 ноября 2020Образование
Никогда так не делайте. Пожалуйста.
Поделиться
0
1. Координально
Как и почему слово «кардинально» превратилось в этого монстра — вопрос, на который у нас нет ответа. «Координаты» и «кардинально» — разные слова. Совсем разные.
2. Вообщем
Никаких компромиссов: или «вообще», или «в общем». Третьего не дано.
3. Учавствовать
Принять учавствие, учавстник — режет глаз, правда? Это всё потому, что в слове «участвовать» две «в». Запомните и не повторяйте эту ошибку впредь.
4. Ться / тся
Каждый раз, когда вы делаете такую ошибку, где‑то плачет Розенталь. Не обижайте Дитмара Эльяшевича. Есть простой способ выяснить, стоит ли ставить мягкий знак в окончании глагола: если глагол отвечает на вопрос «Что делать?» — мягкий знак нужен. «Что делает?» — не нужен.
«Что делает?» — не нужен.
5. Извените
Да ни за что. Лучше сначала всё-таки запомнить, что правильный вариант — «извините», а потом уже просить прощения.
6. Надевать / одевать
Да‑да, про необходимость надевать одежду и Надежду, которую неплохо бы одеть, вам наверняка рассказывали ещё в школе. Ничего, нам не сложно повторить, лишь бы вы запомнили, какое слово в каком случае употребляется.
7. Экспрессо
Хоть как назовите напиток, быстрее вам его вряд ли сделают. Словарная норма — «эспрессо». И так, на всякий случай: в слове «латте» ударение падает на первый слог.
8. До белого колена
Такая интерпретация выражения «до белого каления» вызывает лишь восхищение народной смекалкой. Не знал человек, что такое каление, вот и заменил его на простое и понятное колено. Восполним пробел: каление — это когда металл нагревают, а он от этого светится красным, жёлтым или белым. Если белым — значит, вы его довели.
9. Скрипя сердцем
Сердце — это не телега и даже не потёртое седло, скрипеть там особо нечему. А вот разбиться на кусочки от пренебрежения, с которым люди относятся к русскому языку, оно вполне может. Скрепим его понадёжнее и запомним, что правильный вариант — скрепя сердце.
А вот разбиться на кусочки от пренебрежения, с которым люди относятся к русскому языку, оно вполне может. Скрепим его понадёжнее и запомним, что правильный вариант — скрепя сердце.
10. В течение / в течении
«В течение» — предлог, он связан с каким‑то периодом времени: в течение трёх часов, в течение следующего года. «В течении» — сочетание предлога и существительного, тут речь идёт о течении как потоке воды, например течении реки или ручья. «В течение» можно безболезненно заменить на «во время» — пользуйтесь этим правилом, если есть сомнения.
11. Ихний
Или ещё хуже — ихий. Шутки про одноимённые химические элементы уже всем осточертели, так что обойдёмся без них. Просто запомните: чей? Их.
12. Также / так же
«Также» = «и»: «Читатель Лайфхакера относится со здравой критикой к себе и окружающему миру, а также разумно подходит к решению любых вопросов». Если такая замена ломает смысл предложения — это верный знак, что тут уместен вариант «так же»: «Аркадий Петрович без ума от Лайфхакера, русский язык он любит так же сильно».
13. Обажать
«Обожать», как говорит нам Большой толковый словарь русского языка, означает «боготворить». Как можно догадаться, тут не обошлось без слова «бог». Боже мой, почему же многие норовят написать «обожать» через «а»?
14. Роспись / подпись
Роспись — на стене или потолке, а в документе — подпись. Только так и никак иначе.
15. Ложить
Пожалуйста, выкиньте это слово из активного лексикона раз и навсегда. Правильно — класть.
16. В крации
Лидер топа странных ошибок. «Вкратце» значит «в кратком виде». Что такое крация, мы даже не представляем. И не очень хотим, если честно.
17. В нутри
Видимо, подразумевается, что где‑то есть неведомая нутрь, в которой что‑то происходит. Если так, то ладно, но наречие и предлог «внутрь» лучше всё же писать слитно.
18. Воскресенье / воскресение
Если вы про день недели, то это воскресенье. Если о том, как кто‑то восстал из мёртвых — воскресение. Полагаем, чаще всего вы всё же подразумеваете первый случай.
19. Моё день рождения
Или ещё хлеще: день рождение. На самом деле тут всё просто: день чего? Рождения. День рождения чей? Мой.
20. Крема
В профессиональной среде такой вариант встречается часто, но это не означает, что его следует принять в качестве нормы. Правильно всё-таки «кремы».
21. Агенство
Буква «т» в слове «агент» присутствует не просто так. Помните о ней.
22. Скурупулёзный
Скрупулёзный. Скрупулёзный. Скрупулёзный. Повторяйте, пока не запомните.
23. Через чур
Чур — река в Якшур‑Бодьинском районе Удмуртской Республики. Если вы рассказываете, как переправлялись через неё, тогда «через Чур» — верный вариант. В случаях, когда можно использовать наречие «слишком», необходимо писать «чересчур».
24. Функционал
Если речь идёт о наборе возможностей, например, нового смартфона, единственно верный вариант — функциональность. Функционал — это совсем другое слово, оно про математику. Не путайте, пожалуйста.
25.
 Попробывать
Попробывать
Есть такое правило: если в первом лице единственного числа настоящего или будущего времени глагол заканчивается на -ую или -юю, то в неопределённой форме и в прошедшем времени используются суффиксы -ева-, -ова-. Попробую — попробовать.
26. Экстримальный
Ход мысли понятен: «экстрим» ведь пишется через «и». Но нет, не всё так просто. «Экстрим» — относительно недавнее заимствование из английского языка, а слово «экстремальный» пришло в русский язык из французского, который позаимствовал его из латыни. Сюрприз, но эти слова не могут быть проверочными друг для друга.
27. Комфорка
Хоть это слово кажется ещё одним из серии «тубаретка в колидоре», такой вариант написания когда‑то считался вполне приемлемым. В толковом словаре Ушакова, выходившем в 1935–1940 годах, упоминались и конфорка, и комфорка. Впрочем, теперь разногласий нет: Большой толковый словарь Кузнецова рекомендует именно вариант «конфорка».
28. Из‑под тишка
Школьный этимологический словарь русского языка спешит сообщить, что здесь мы наблюдаем сращение «из‑под тишка», где тишок — тишина или спокойствие. В итоге получилось «исподтишка».
В итоге получилось «исподтишка».
29. Подскользнуться
Шёл человек по скользкому льду да и поскользнулся. Никакой «д» там нет.
30. Симпотичный
Проверочное слово — «симпатия». Значит, верный вариант — «симпатичный». Запомните и передайте другим.
Мы уверены, что вы сможете дополнить наш список. Делитесь в комментариях ошибками, которые вас бесят.
Читайте также 🧐
- 44 слова, которые мы употребляем неправильно
- 20 выражений, в которых все вокруг делают ошибки
- 10 смысловых ошибок, которые мешают понять друг друга, и способы их избежать
Ученые назвали 10 ошибок в речи, за которые больше всего стыдно
Вместе с профессором Азалией Блиновой, заведующей кафедрой сценической речи Екатеринбургского театрального института, мы составили топ-10 речевых ошибок, за которые бывает мучительно стыдно. Если не за себя, то за тех, кто так говорит.
Если не за себя, то за тех, кто так говорит.
Все звОнит и звОнит
Лидер рейтинга — «звОнит». Неправильное ударение в этом слове, как отмечает Азалия Блинова, с головой выдает невысокий культурный уровень человека. И как бы он ни пытался умничать и говорить красиво, от одного «звОнит» впечатление от общения бывает смазано. Правильно только — «звонИт».
«Посмотрите на евонное личико»
Помню, как в детстве, в лагере мы ставили «Золушку». Короля в ней играл самый настоящий отпетый хулиган. В самый напряженный момент действа, восседая на троне, он с пафосом обратился к залу, указывая на принца: «Да вы только посмотрите на евонное личико!».
Дальше уже никто не мог смотреть спектакль без смеха. А «король» искренне не понимал, что происходит. Ему и сегодня напоминают при встрече про «евонное личико».
«Ихние», «евонные», как говорит профессор Блинова, явные просторечья, причем, относящиеся к уральским диалектизмам. И как бы ни обидно звучало для человека, который так говорит, но сразу понимаешь, что детство он провел в среде людей с не самым высоким уровнем грамотности. Что, конечно, не приговор. Нужно самому больше читать, развиваться, впитывая образцы правильной речи.
Что, конечно, не приговор. Нужно самому больше читать, развиваться, впитывая образцы правильной речи.
Все «ложат» и «ложат»
Можно положить, но нельзя «ложить». Слово без приставки не существует. Поэтому если не хотите прослыть неграмотным, не ляпните где-нибудь — «ложат книги на полку» или «ложат кирпичи».
«Почему они не «плотят»?
Ну, кто не слышал, как, к примеру, кондуктор в трамвае говорит «а что это они там за проезд не плотят»? Здесь не только речевая ошибка, но и грамматическая, говорит Азалия Блинова. И к тому же это типичное уральское просторечное выражение. В основе слова — «плАта», и потому за проезд можно только «заплатить».
Подпишите договорА
Правильно — только договОры, отмечает наш эксперт. По мнению Азалии Блиновой, эта ошибка зародилась еще во времена Хрущева, когда южный просторечный диалектизм распространился по всему Союзу и зажил своей вполне успешной «чиновничьей» жизнью.
А было это в «двухтысячно первом году»
Зато у нынешних чиновников в ходу другой речевой «перл». Читает кто-нибудь из них доклад и серьезно так, не смущаясь, говорит: «В двухтысячном первом году мы увеличили производственные мощности». А тут смех в зале.
Читает кто-нибудь из них доклад и серьезно так, не смущаясь, говорит: «В двухтысячном первом году мы увеличили производственные мощности». А тут смех в зале.
Конечно, нельзя так склонять числительные, говорит Азалия Блинова, правильно — «в две тысячи первом году». И чиновнику, прежде чем выходить за трибуну, не лишне было бы подготовиться.
«Мы стали более лучше одеваться»
Ну, это уже «классика жанра», — фраза Светы из Иваново, моментально ставшая мемом. Бедная Света сразу и не поняла, почему над ней подтрунивают. А всего-то из-за того, что пыталась сказать красиво и допустила избыточное в данном случае — «более». «Мы стали лучше одеваться» — вот как правильно.
Мы пили на Монмартре кофе «экспрессо»
Думаете, никто уже не говорит «экспрессо»? Да совсем недавно услышала от знакомого, вернувшегося из Парижа. Он с пафосом произнес «Мы пили на Монмартре кофе экспрессо». Как говорит профессор Азалия Блинова, на экспрессе ездят, а эспрессо — пьют. Эспрессо — это способ приготовления кофе. А сам «кофе», к слову, мужского рода, если кто забыл.
Эспрессо — это способ приготовления кофе. А сам «кофе», к слову, мужского рода, если кто забыл.
Надела кофту новую
Еще одна распространенная ошибка — путаница в понятиях » надевать и одевать». Надеть можно на себя, а одеть кого-то.
Не тортЫ, а тОрты
И замыкает десятку речевых огрехов самое «вкусное» — тортЫ, и тут все, конечно, знают, как правильно, но нет-нет да и услышишь, как режет слух «тортЫ».
В тему
Как самому научиться говорить красиво и правильно:
1. Развивать речевой слух. Больше читать и слушать образцы правильной литературной речи. Например, аудио спектакли по классическим произведениям в исполнении актеров еще советского времени. Или аудиокниги, тексты которых записывают хорошие чтецы. Чаще посещать театр.
2. Устраивать себе «уроки подражания» хорошей речи. Слушать, как например, читает стихи известный актер, а затем пытаться самому прочесть так же. И так до тех пор, пока не получится.
И так до тех пор, пока не получится.
3. Не зажимать нижнюю челюсть. Расслабиться на мышечном уровне. Выпрямить спину, чтобы потоки воздуха при дыхании проходили свободно, чтобы ничего не мешало говорить.
4. Четко проговаривать ударную и предударную гласные. Не смазывать окончания глаголов.
5. Незачем говорить четко по написанному. У устной речи — свои законы. Поэтому — читай пункт 1.
Типичные ошибки в русском языке: грамматические, речевые
Наши курсы призваны помочь школьникам успешно подготовиться к ЕГЭ и стать студентами медицинских вузов. Мы предлагаем глубокие знания как для подготовки к профильным ЕГЭ по химии и биологии, так и к ЕГЭ по русскому языку.
В этой статье познакомимся с классификацией типичных ошибок в русском языке и разберем их на конкретных примерах.
Классификация ошибок по ФИПИ
Составители КИМов ЕГЭ по русскому языку предлагают следующую классификацию, которая используется при проверке письменного задания. Итак, типичные ошибки подразделяются на:
Итак, типичные ошибки подразделяются на:
Рассмотрим каждый вид подробнее.
Виды грамматических ошибок
Грамматические ошибки заключаются в неправильном образовании слов и их грамматических форм, в нарушении синтаксической связи между словами в словосочетании и предложении.
Ознакомимся с типичными грамматическими ошибками в русском языке.
Ошибочное словообразование
Подскользнуться (нужно писать поскользнуться).
Неправильное образование формы существительного
Многочисленные договора (нужно: многочисленные договоры).
Неверное образование формы прилагательного
Не более громче, а более громкий, не самый старейший, а самый старый
Неправильное образование формы числительного
Около пятиста участников вместо пятисот участников
Неверное образование формы местоимения
Ихний сын (правильно: их сын).
Неправильное образование форм глаголов, причастий, деепричастий
Махает (правильно: машет)
Скакающий (верно: скачущий),
Положа трубку вместо положив
Нарушение согласования
Он восхищается студентами, напролом идущих к своей цели (правильно: студентами, идущими к своей цели).
Нарушение управления
Анна Александровна не поздравила с день рожденья.
(правильно: не поздравила с днём рождения).
Нарушение связи между подлежащим и сказуемым
Все, кто советуют не пользоваться гаджетами перед сном, обычно сами пренебрегают этим правилом (правильно: кто советует).
Ошибочное построение предложений с причастным и деепричастным оборотами
Классический пример: Подъезжая к станции, у меня слетела шляпа.
Смешение прямой и косвенной речи
Директор заявил, что я накажу виновных.
(Правильно: директор заявил, что он накажет виновных).
Нарушение границ предложения
Аня, наверное, испугалась. Потому что вздрогнула и обернулась (необходимо оформить как сложноподчиненное предложение).
Виды речевых ошибок
Речевая ошибка – это нарушение в структуре употребления и сочетаемости слов.
Постарайтесь запомнить типичные речевые ошибки в русском языке и не употреблять их в своих высказываниях.
Употребление слова в не подходящем для него значении
Благодаря землетрясению, были разрушены сотни жилых домов (следовало употребить предлог из-за).
Плеоназм
Он откликается на всесвободные вакансии (слово вакансия означает свободное рабочее место).
Тавтология
В своем рассказе автор рассказывает о событиях прошлого лета.
Неудачное употребление местоимений
Лена очень любила свою подругу. Она была очень доброй и заботливой.
Неправильное употребление паронимов
В решении этого вопроса были приняты эффектные меры (следует употребить эффективные меры).
Нарушение лексической сочетаемости
Евгений постоянно пополняет свой кругозор. Работа занимает важную роль в его жизни (правильно: кругозор расширяют; занимает важное место либо играет важную роль).
Неоправданное употребление просторечий, жаргонизмов
Автор не ожидал такого кринжа.
Логические ошибки – это высказывания, в которых есть внутреннее противоречие, нарушение логики изложения мысли. Такие ошибки тоже не редко встречаются в работах ЕГЭ по русскому языку.
Такие ошибки тоже не редко встречаются в работах ЕГЭ по русскому языку.
Подмена понятий
Автор поднимает проблему патриотизма. Эта тема очень важна в наше время (тема и проблема – далеко не одно и то же).
Вскоре она перестала плакать, так как успокоилась.
Автор задумывается о роли воспитания в жизни ребенка. И действительно, детям нужно заботиться о животных, чтобы привить чувство ответственности.
Фактические ошибки
Фактическая ошибка – это искажение информации о событиях и лицах, упоминаемых в тексте сочинения.
Автор с упоением отзывается о писателе А. Эйнштейне.
Все смешалось в доме Обломовых.
Орфографические, графические, пунктуационные ошибки
Орфографическая ошибка – это неправильное написание слова. К типичным орфографическим ошибкам в русском языке относятся:
Правописание букв в слабой позиции перехот(переход)
Нарушения в переносе слов рад-ость
Слитное или раздельное написание слов какбудто, не чем (как будто, нечем)
Правописание чередующихся корней умерать (умирать)
Правописание словарных слов.
 Например, поменяться кординально (кардинально)
Например, поменяться кординально (кардинально)
Совет: если вы сомневаетесь в написании слова, не используйте его, а замените синонимом, в написании которого вы уверены.
Графические ошибки – это перестановка (полувер) либо пропуск букв (рассморение), а иногда добавление лишних букв (дажбе). Чаще всего эти недочёты связаны с невнимательностью пишущего либо с торопливостью.
Пунктуационные ошибки связаны с неправильной постановкой знаков препинания, неверного их выбора (запятая на месте тире).
К типичным ошибкам в ЕГЭ по русскому языку, связанным с пунктуацией, относятся:
неверное оформление прямой речи на письме,
невыделение уточняющих слов, причастных и деепричастных оборотов.
Хотя наиболее частыми являются именно грамматические ошибки в ЕГЭ по русскому языку, обратите внимание и на все остальные.
Совет: найдите в интернете текст с ошибками и отредактируйте его, выделив в нем все виды ошибок. Такое упражнение поможет вам стать грамотнее и прибавит чувство уверенности при написании сочинения на ЕГЭ.
А если ваша подготовка к ЕГЭ зашла в тупик и вы не знаете, с чего начать, либо у вас остались вопросы, то скорее записывайтесь на наши курсы!
Речевые ошибки: примеры и виды
Все люди, хоть раз в жизни, да допускают речевые ошибки. Примеры исчисляются тысячами, особенно если это касается русского языка, который, как известно, отличается богатством и разнообразием. Но говорить нужно грамотно, потому лучше заниматься развитием своей речи. Для собственного развития стоит узнать, какие виды речевых ошибок существуют и что нужно делать, чтобы избежать их употребления.
Речь и её специфика
Речь – это абстрактная категория, которую непосредственно воспринять никак не получится. Также это важный показатель человеческой культуры, мышления и, конечно же, интеллекта. Разговаривая, можно познать многие вещи, разобраться в сложностях, связанных с обществом, природой, и передать полученную информацию коммуникативным путём. Но ошибки делают все – как в устной, так и в письменной речи. И чтобы добиться совершенства в плане знания русского языка, надо распознавать все ошибки – начиная стилистическими, заканчивая речевыми. И для начала хотелось бы затронуть тему понятий. Что собой представляют речевые ошибки в русском языке? Это отклонение от существующих языковых норм. Можно спокойно жить, не зная о них, однако насколько будет эффективно общение такого человека с остальными – это вопрос. Он просто может быть неправильно понят.
Разговаривая, можно познать многие вещи, разобраться в сложностях, связанных с обществом, природой, и передать полученную информацию коммуникативным путём. Но ошибки делают все – как в устной, так и в письменной речи. И чтобы добиться совершенства в плане знания русского языка, надо распознавать все ошибки – начиная стилистическими, заканчивая речевыми. И для начала хотелось бы затронуть тему понятий. Что собой представляют речевые ошибки в русском языке? Это отклонение от существующих языковых норм. Можно спокойно жить, не зная о них, однако насколько будет эффективно общение такого человека с остальными – это вопрос. Он просто может быть неправильно понят.
Произношение
Стоит вкратце перечислить виды речевых ошибок, которые существуют в русском языке. Итак, это произносительные, лексические, фразеологические, стилистические, орфографические, морфологические, пунктуационные и, наконец, синтаксические. К первым из перечисленных относятся те ошибки, которые допущены из-за нарушения орфоэпии. Самые часто встречающиеся речевые ошибки в русском языке. Если человек говорит вместо “почти” слово “пошти”, путает ударения (“а́лкоголь” – “алкого́ль”), сокращает “тысячу” до “тыщи” – это значит то, что он допускает такие помарки, которые для носителя языка являются позорными.
Самые часто встречающиеся речевые ошибки в русском языке. Если человек говорит вместо “почти” слово “пошти”, путает ударения (“а́лкоголь” – “алкого́ль”), сокращает “тысячу” до “тыщи” – это значит то, что он допускает такие помарки, которые для носителя языка являются позорными.
Лексикология
Говоря про типы речевых ошибок, нельзя не затронуть вниманием лексические. Они также встречаются довольно часто. К таковым относятся те помарки, которые случаются из-за употребления фраз или слова в том значении, что является для них несвойственным. Таким образом искажается морфемная форма слов, а также правила смыслового согласования. Кстати, в лексикологии также существует классификация речевых ошибок. Есть три типа. К первому относится смешение тех слов, которые близки между собой по значению. Некоторые умудряются выразиться таким образом: “Я пешком постою”. Второй вид – это смешение тех слов, что близки по звучанию. Встречается довольно часто: одинарный – ординарный, кларнет – корнет, эскалатор – экскаватор и т. д. И наконец, третий вид ошибок – это смешений слов, которые близки и по звучанию, и по значению. Часто путают адресанта с адресатом, а дипломанта с дипломатом. Нельзя не сказать об “авторских” ошибках. Если быть точнее, то о сочинительстве несуществующих слов. Например, “грузинец”, “мотовщик”, “героичество” и т.д.
д. И наконец, третий вид ошибок – это смешений слов, которые близки и по звучанию, и по значению. Часто путают адресанта с адресатом, а дипломанта с дипломатом. Нельзя не сказать об “авторских” ошибках. Если быть точнее, то о сочинительстве несуществующих слов. Например, “грузинец”, “мотовщик”, “героичество” и т.д.
Смысловое согласование
Нарушение смысла предложения путём введения в него неподходящего слова — это тоже частые речевые ошибки. Примеры можно взять из повседневной жизни: “Я поднимаю этот тост”. Так говорить нельзя, ведь “поднять” – значит переместить что-то. А тост – это торжественные слова. Их поднять никак не получится. Потому лучше в данном случае либо “тост” заменить словом “бокал” либо же вместо “поднимаю” сказать “произношу”. В обоих случаях будет и грамотно, и логично. Кстати, на этом же примере можно понять, как определить речевую ошибку и что нужно сделать, чтобы избежать её вообще. Перед тем как произнести фразу, в правильности которой есть сомнения, следует вспомнить значение слов, участвующих в её построении. Как в случае с приведенным примером. Также часто встречаются в речи тавтологии и так называемые плеоназмы. К последним относятся сочетания двух слов, являющихся полностью идентичными. Самый яркий пример – это фраза “огромный мегаполис”. Лучше сказать “большой город”. Ведь “мегаполис” так и переводится, потому не нужно сюда добавлять определение “огромный”. Анализируя, таким образом, всё, что хочется произнести, получится избежать массы ошибок. К тому же такие тренировки развивают речь и мышление. И наконец, тавтология. Тут всё просто: “видел видео”, “стрелял стрелами”, “задала задание”, “сделал дело” и т.д. Тут спасают синонимы – можно заменить одно слово на другое — и фраза уже будет смотреться более логично.
Как в случае с приведенным примером. Также часто встречаются в речи тавтологии и так называемые плеоназмы. К последним относятся сочетания двух слов, являющихся полностью идентичными. Самый яркий пример – это фраза “огромный мегаполис”. Лучше сказать “большой город”. Ведь “мегаполис” так и переводится, потому не нужно сюда добавлять определение “огромный”. Анализируя, таким образом, всё, что хочется произнести, получится избежать массы ошибок. К тому же такие тренировки развивают речь и мышление. И наконец, тавтология. Тут всё просто: “видел видео”, “стрелял стрелами”, “задала задание”, “сделал дело” и т.д. Тут спасают синонимы – можно заменить одно слово на другое — и фраза уже будет смотреться более логично.
Морфологическая и синтаксическая неграмотность
Предложения с речевыми ошибками, относящимися к морфологическим, можно слышать каждый день – на рынке, в метро, на улице, в магазине. Речь идёт о неправильном образовании того или иного слова. Людям, которые хорошо владеют русским, такие “перлы” режут слух. Допустим, “сыграй на пианине”, “там было дешевше”, “одна джинса”, “тот полотенец” и т.д. В данном случае нужно просто заучивать слова, чтобы не употреблять в неправильной форме. Синтаксические ошибки заключаются в неправильном сочетании слов. “Чтение Есенина произвело огромное впечатление” – тут возникает логичный вопрос, читали его произведения, или же читал сам Сергей Александрович? Или, например, такое предложение: “На полке стоят много банок” — тут явное неправильное согласование. И таких примеров масса. Некоторые люди так говорят случайно, в спешке, другие – из-за незнания. В любом случае стоит исправлять себя, чтобы собеседник не посчитал своего оппонента безграмотным.
Допустим, “сыграй на пианине”, “там было дешевше”, “одна джинса”, “тот полотенец” и т.д. В данном случае нужно просто заучивать слова, чтобы не употреблять в неправильной форме. Синтаксические ошибки заключаются в неправильном сочетании слов. “Чтение Есенина произвело огромное впечатление” – тут возникает логичный вопрос, читали его произведения, или же читал сам Сергей Александрович? Или, например, такое предложение: “На полке стоят много банок” — тут явное неправильное согласование. И таких примеров масса. Некоторые люди так говорят случайно, в спешке, другие – из-за незнания. В любом случае стоит исправлять себя, чтобы собеседник не посчитал своего оппонента безграмотным.
Правила написания
Грамматические и речевые ошибки люди совершают не только в процессе живого общения. Многие допускают помарки во время переписок, составления отчетов, написании текстов. К таковым относятся орфографические ошибки. Их человек допускает из-за того, что он не знает, как нужно переносить, писать или сокращать слова. Забывают ставить две “нн” вместо одной, вместо “о” пишут “а”, пренебрегают мягкими знаками в окончаниях глаголов на “ш”. Ошибки могут быть незначительными (допустим, человек пропустил букву, промахнувшись мимо клавиши), а существуют и откровенные несуразицы. Был даже случай, когда школьник допустил в слове “ёж” четыре ошибки, написав “иошь”. Однако это ребёнок, который только учится, а когда взрослые, состоявшиеся личности совершают абсурдные помарки, это как минимум странно. Потому нужно следить за своей речью, чтобы, как говорится, не попасть впросак.
Забывают ставить две “нн” вместо одной, вместо “о” пишут “а”, пренебрегают мягкими знаками в окончаниях глаголов на “ш”. Ошибки могут быть незначительными (допустим, человек пропустил букву, промахнувшись мимо клавиши), а существуют и откровенные несуразицы. Был даже случай, когда школьник допустил в слове “ёж” четыре ошибки, написав “иошь”. Однако это ребёнок, который только учится, а когда взрослые, состоявшиеся личности совершают абсурдные помарки, это как минимум странно. Потому нужно следить за своей речью, чтобы, как говорится, не попасть впросак.
Логика в речи
Наша речь должна быть логичной – это известно всем. Потому надо стараться не нарушать причинно-следственные отношения, не пропускать звена в своих объяснениях, не переставлять части предложения и, конечно же, не “бежать” вперёди своей мысли. Чтобы понятно изъясняться, нужно преподносить информацию такой, какой её могут усвоить собеседники. Это не так трудно, нужно просто сконцентрироваться на своей мысли.
Расширенная классификация
Были рассмотрены многие речевые ошибки, примеры которых наглядно показывают, в чём именно заключается тот или иной недочет. Но на самом деле видов подобных “помарок” намного больше, расширенная классификация речевых ошибок, соответственно, более объемна. Взять, к примеру, ошибки, заключающиеся в неоправданном употреблении определенных слов. “Благодаря тебе он заболел” – предложения, подобные этому, встречаются очень часто. Употребление слова “благодаря” здесь невозможно, поскольку оно несет совершенно иную эмоциональную окраску. А порой люди допускают такие ошибки, которые даже звучат смешно. Например, “«Нос» Гоголя наполнен глубоким смыслом” или “Во двор въехали две лошади. Это были сыновья Тараса Бульбы” – очень неудачно употреблены местоимения. Кстати, к речевым ошибкам также можно отнести бедность лексики человека. Обычно это объясняется его небольшим словарным запасом. Он часто употребляет одни и те же слова, много повторяется. Этого тоже надо избегать.
Но на самом деле видов подобных “помарок” намного больше, расширенная классификация речевых ошибок, соответственно, более объемна. Взять, к примеру, ошибки, заключающиеся в неоправданном употреблении определенных слов. “Благодаря тебе он заболел” – предложения, подобные этому, встречаются очень часто. Употребление слова “благодаря” здесь невозможно, поскольку оно несет совершенно иную эмоциональную окраску. А порой люди допускают такие ошибки, которые даже звучат смешно. Например, “«Нос» Гоголя наполнен глубоким смыслом” или “Во двор въехали две лошади. Это были сыновья Тараса Бульбы” – очень неудачно употреблены местоимения. Кстати, к речевым ошибкам также можно отнести бедность лексики человека. Обычно это объясняется его небольшим словарным запасом. Он часто употребляет одни и те же слова, много повторяется. Этого тоже надо избегать.
Развитие речи
Рассмотрев речевые ошибки, примеры таковых и выяснив природу их возникновения, можно понять, что грамотно разговаривать – это не так-то просто. А ведь практически каждый человек хочет изъясняться так, чтобы его понимали. Для этого нужно постоянно работать над собой и своей речью, развивая её. Как предупредить речевые ошибки? Для этого нужно читать художественную литературу, посещать выставки, музеи и театры, разговаривать с умными и образованными личностями. Всё это нужно, чтобы расширить свой словарный запас и набраться опыта в плане употребления тех или иных слов. Кстати, между подобным развитием речи и изучением иностранного языка можно провести параллель. Ведь все знают, что человек, попадая в языковую среду, усваивает его лучше. В данном случае то же самое – больше общаясь с грамотными людьми и уделяя время культурным мероприятиям, можно стать образованнее.
А ведь практически каждый человек хочет изъясняться так, чтобы его понимали. Для этого нужно постоянно работать над собой и своей речью, развивая её. Как предупредить речевые ошибки? Для этого нужно читать художественную литературу, посещать выставки, музеи и театры, разговаривать с умными и образованными личностями. Всё это нужно, чтобы расширить свой словарный запас и набраться опыта в плане употребления тех или иных слов. Кстати, между подобным развитием речи и изучением иностранного языка можно провести параллель. Ведь все знают, что человек, попадая в языковую среду, усваивает его лучше. В данном случае то же самое – больше общаясь с грамотными людьми и уделяя время культурным мероприятиям, можно стать образованнее.
речевых ошибок и что они говорят о языке
«Они недооценили меня», — печально известное заявление Джорджа Буша-младшего в речи 2000 года о его неожиданной победе над соперником Джоном Маккейном. Это лишь одна из многих речевых ошибок, которые Джордж Буш допускал в своей президентской карьере, но она подчеркивает важный момент: никто не говорит идеально, даже высокопоставленные политики, которые хорошо разбираются в публичных выступлениях и, по-видимому, отрепетировали свои выступления. выступления развернуто.
выступления развернуто.
Самыми известными речевыми ошибками являются оговорки по Фрейду, когда говорящий непреднамеренно раскрывает свои истинные чувства, нарушая видимость вежливости и создавая неловкую ситуацию. Например, отец, встретив своего зятя, может случайно произнести « Безумный , чтобы познакомиться с тобой» вместо «Рад познакомиться». Действительно, оговорки по Фрейду забавны, но они представляют собой лишь малую толику реальных речевых ошибок, которые допускают люди.
На первый взгляд, речевые ошибки в реальной жизни могут быть менее занимательными, чем оговорки по Фрейду. Однако понимание, которое они дают нам в отношении нашего ментального лексикона и когнитивных основ языка, далеко не банально. Давайте рассмотрим некоторые из наиболее распространенных речевых ошибок и разберем их, чтобы увидеть, что они говорят о том, как мы понимаем и обрабатываем язык.
Фонологические ошибки
Некоторые речевые ошибки относятся к фонологическим или относятся к звукам языка. Хотя существует множество способов, которыми люди могут произносить слова неправильно, мы рассмотрим две очень распространенные фонологические ошибки: ожидание и настойчивость . Персеверация возникает, когда звук из предыдущего слова проникает в более позднее слово. Вот несколько примеров настойчивости:
Хотя существует множество способов, которыми люди могут произносить слова неправильно, мы рассмотрим две очень распространенные фонологические ошибки: ожидание и настойчивость . Персеверация возникает, когда звук из предыдущего слова проникает в более позднее слово. Вот несколько примеров настойчивости:
- Он пинал жестяная банка (вместо жестяная банка ).
- Нашли сотню долларовых укропов (вместо долларовой купюры ).
Антиципация противоположна персеверации: она возникает, когда говорящий ошибочно использует звук из слова, которое следует позже в высказывании. Некоторые примеры:
- Она выпила раскладную чашку чая (вместо горячей чашки чая).
- На нем был браслет погоды (вместо кожаного браслета ).
Легко интуитивно понять, что происходит с ошибками персеверации: наши языки, столкнувшись с пугающей задачей произнесения множества разных звуков за очень короткое время, просто запутались и произвели звук из предыдущего слова. Однако ошибки предвосхищения, когда мы неправильно используем звук из слова, в котором еще не произнесено , предполагают, что происходит что-то еще.
Однако ошибки предвосхищения, когда мы неправильно используем звук из слова, в котором еще не произнесено , предполагают, что происходит что-то еще.
Действительно, лингвисты считают, что наличие ошибок предвосхищения предполагает, что наш мозг планирует все наши высказывания, даже когда мы говорим спонтанно. То есть еще до того, как мы начнем говорить, все предложение доступно на каком-то базовом уровне в нашем мозгу. По этой причине слова, которые еще не были сказаны, могут загрязнять нашу речь и вызывать ошибки ожидания.
Ошибки замены
Другой распространенный тип ошибок возникает, когда говорящий заменяет целое слово на другое слово, отличное от предполагаемого. Вот некоторые примеры:
- Мое резюме слишком длинное (вместо короткое ).
- Посмотрите на эту милую маленькую собачку (вместо кота ).
Как показывают приведенные выше примеры, ошибочно замененное слово не является случайным. Вместо этого большинство ошибок подстановки имеют несколько общих черт. Во-первых, заменяемое слово и подразумеваемое слово почти всегда одного и того же слова.0007 синтаксический класс — «короткий» и «длинный» являются прилагательными; «собака» и «кошка» — существительные. Вы редко услышите, как кто-то скажет: «Мое резюме — это слишком много работы» или «Посмотрите на этого милого пушистого». Во-вторых, заменяемое слово и предполагаемое слово обычно имеют общую семантическую основу. «Короткий» и «длинный» являются мерами длины; «собака» и «кошка» — пушистые питомцы. Маловероятно, что кто-то случайно скажет: «Мое резюме слишком зеленое» или «Посмотрите на эту симпатичную маленькую лодочку».
Вместо этого большинство ошибок подстановки имеют несколько общих черт. Во-первых, заменяемое слово и подразумеваемое слово почти всегда одного и того же слова.0007 синтаксический класс — «короткий» и «длинный» являются прилагательными; «собака» и «кошка» — существительные. Вы редко услышите, как кто-то скажет: «Мое резюме — это слишком много работы» или «Посмотрите на этого милого пушистого». Во-вторых, заменяемое слово и предполагаемое слово обычно имеют общую семантическую основу. «Короткий» и «длинный» являются мерами длины; «собака» и «кошка» — пушистые питомцы. Маловероятно, что кто-то случайно скажет: «Мое резюме слишком зеленое» или «Посмотрите на эту симпатичную маленькую лодочку».
Это говорит о том, что слова структурированы в нашем мозгу в отношении как синтаксис — какая часть речи слова мы — и семантика — что означают слова. По этой причине ошибки замены почти всегда возникают среди синтаксически и семантически близких слов.
Иноязычные ошибки
Большинство исследований речевых ошибок проводится с говорящими на их родном языке. Тем не менее, были проведены некоторые исследования различных типов речевых ошибок, допускаемых носителями языка и теми, кто выучил язык в более позднем возрасте. Неудивительно, что не носители языка совершают в среднем больше ошибок, чем их носители языка. Однако при осмотре типов ошибок, допущенных носителями и не носителями языка, выявились некоторые интересные закономерности.
Тем не менее, были проведены некоторые исследования различных типов речевых ошибок, допускаемых носителями языка и теми, кто выучил язык в более позднем возрасте. Неудивительно, что не носители языка совершают в среднем больше ошибок, чем их носители языка. Однако при осмотре типов ошибок, допущенных носителями и не носителями языка, выявились некоторые интересные закономерности.
Неносители языка иногда заменяют слова из своего первого языка на свой второй язык. Например, носитель английского языка, изучающий испанский, может сказать «Это важно», используя английское слово «это» вместо испанского эквивалента «эсо». Однако эти замены не были случайными. Они произошли в основном в функции слов, то есть такие слова, как артикли («the», «a») и предлоги («with», «to»), которые грамматически необходимы, но сами по себе не имеют никакого значения.
Следовательно, используя приведенный выше пример, носитель английского языка с большей вероятностью скажет «You quiero a hamburguesa», учитывая, что «a» является служебным словом. Эти ошибки предполагают, что служебные слова более глубоко укоренились в нашем мозгу, чем другие слова. Это также может объяснить, почему темы, связанные со служебными словами, такие как правильное использование артиклей, союзов и предлогов, часто представляют собой особую проблему для изучающих язык.
Эти ошибки предполагают, что служебные слова более глубоко укоренились в нашем мозгу, чем другие слова. Это также может объяснить, почему темы, связанные со служебными словами, такие как правильное использование артиклей, союзов и предлогов, часто представляют собой особую проблему для изучающих язык.
В конце концов, речевые ошибки — это нечто большее, чем оговорки по Фрейду. В самом деле, оговорки могут не так раскрывать наши внутренние желания, как мог подумать Фрейд, но они остаются интересными сами по себе. Они демонстрируют нам, что мы строим планы для наших высказываний даже в спонтанной речи, когда мы этого не осознаем. Они показывают нам, что наш мозг классифицирует слова на основе их синтаксических и семантических свойств. И они демонстрируют нам, что определенные классы слов лучше укоренились в нашем мозгу, чем другие, что дает представление об изучении и обработке второго языка.
Об авторе
Пол пишет от имени Language Trainers, службы языкового обучения, предлагающей индивидуальные пакеты курсов для отдельных лиц и групп. Ознакомьтесь с их бесплатными тестами на аудирование на иностранном языке и другими ресурсами на их веб-сайте. Посетите их страницу в Facebook или свяжитесь с нами по адресу [email protected], если у вас возникнут вопросы.
Ознакомьтесь с их бесплатными тестами на аудирование на иностранном языке и другими ресурсами на их веб-сайте. Посетите их страницу в Facebook или свяжитесь с нами по адресу [email protected], если у вас возникнут вопросы.
Системы письма |
Язык и языки |
Изучение языков |
Произношение |
Изучение словарного запаса |
Приобретение языка |
Мотивация и причины изучать языки |
арабский |
баскский |
кельтские языки |
китайский |
Английский |
эсперанто |
французский |
немецкий |
Греческий |
иврит |
индонезийский |
итальянский |
японский |
Корейский |
латинский |
португальский |
Русский |
Языки жестов |
испанский |
Шведский |
Другие языки |
Языки меньшинств и исчезающие языки |
Искусственные языки (конланги) |
Отзывы о языковых курсах и книгах |
Приложения для изучения языков |
Преподавание языков |
Языки и карьера |
Быть и становиться двуязычным |
Язык и культура |
Развитие речи и расстройства |
Письменный и устный перевод |
Многоязычные сайты, базы данных и программирование |
История |
Путешествия |
Еда |
Другие темы |
Поддельные статьи |
Как подать статью
[сверху]
Почему бы не поделиться этой страницей:
Изучайте языки бесплатно на Duolingo
Если вам нравится этот сайт и вы считаете его полезным, вы можете поддержать его, сделав пожертвование через PayPal или Patreon или пожертвовав другим способом. Омниглот — это то, как я зарабатываю на жизнь.
Омниглот — это то, как я зарабатываю на жизнь.
Примечание : все ссылки на этом сайте на Amazon.com, Amazon.co.uk и Amazon.fr являются партнерскими ссылками. Это означает, что я получаю комиссию, если вы нажимаете на любой из них и что-то покупаете. Таким образом, нажав на эти ссылки, вы можете помочь поддержать этот сайт.
[сверху]
Психолингвистика — Речевые ошибки — GRIN
Содержание
1 Введение
2 Левельтовская модель речевого производства
2.1 Теория слотов и заполнителей
3 Типы речевых ошибок
3.1 Смеси
3.1.1 Комбинации слов
3.1.2 Сочетания фраз
3.2 Замены
3.2.1 Замена слова
3.2.2 Замена одного звука другим
3.3 Обмен
3.3.1 Обмен словами
3.3.2 Обмен фразами
3.3.3 Обмен звуками
3.3.4 Обмен группами согласных
3.3.5 Обмен морфемами
3.3.6 Обмен признаками
4 Объяснение некоторых речевых ошибок по модели Левельта
5 Модель речевого производства Гарретта
5. 1 Объяснение некоторых речевых ошибок в соответствии с моделью Гарретта
1 Объяснение некоторых речевых ошибок в соответствии с моделью Гарретта
6 Резюме
Библиография
1 Введение
Речевые ошибки — это ошибки в спонтанной речи, а не продукт преднамеренной неграмматичности или диалектов.
Они возникают, когда фактическое высказывание говорящего каким-либо образом отличается от предполагаемого высказывания, так называемая цель. Вопрос в том, какие речевые ошибки могут возникать и как эти ошибки можно объяснить с помощью различных моделей речеобразования.
Моя курсовая работа посвящена различным типам речевых ошибок и двум важным моделям речи Левельта и Гарретта.
Сначала я представлю модель речи Левельта. Затем я объясню различные типы речевых ошибок со ссылкой на эту модель.
В главе 4 я приведу собственные примеры речевых ошибок немецкого языка из повседневной жизни и телевидения, попытаюсь поместить их в модель Левельта и объяснить их.
Затем я представлю модель производства речи Гарретта и приведу два примера речевых ошибок со ссылкой на эту модель.
В конце курсовой работы я подведу краткие итоги и кратко сравним две модели.
2 Левельтовская модель речевого производства
иллюстрация, не показанная в этом отрывке
Рисунок взят из: Levelt (1989, p.9)
Беглая речь состоит из ряда компонентов обработки, которые показаны в модели Levelt (1989) выше. Прямоугольники в этой модели представляют компоненты обработки, а круг и эллипс — хранилища знаний.
«Чертеж говорящего» состоит из следующих компонентов:
(1) Концептуализатор : Концептуализатор выбирает соответствующую информацию, заказывает эту информацию для выражения и так далее; этот процесс называется «концептуализацией». Наконец, он генерирует довербальное сообщение. Чтобы закодировать сообщение, говорящему необходимы два вида знаний:
– процессуальное знание, имеющее формат «если х, то у». Это знание ситуации.
– декларативное знание, которое часто является пропозициональным знанием.
(2) Formulator : Он переводит довербальное сообщение в лингвистическую структуру и создает на выходе фонетический или артикуляционный план. Перевод выполняется в два этапа:
Перевод выполняется в два этапа:
— Грамматическое кодирование ; здесь извлекаются леммы из лексикона и генерируются грамматические отношения, отражающие концептуальные отношения в сообщении. Его вывод называется «поверхностной структурой», которая представляет собой упорядоченную строку лемм, сгруппированных во фразы и подфразы.
— Фонологическое кодирование ; здесь фонетический план создается на основе поверхностной структуры.
(3) Артикулятор : До сих пор еще ничего не было сказано. Артикулятор разворачивает и выполняет фонетический план, а продуктом артикуляции является открытая речь. Артикуляционный буфер помогает временно сохранить фонетический план.
(4) Система понимания речи : Этот компонент позволяет говорящему контролировать его собственное производство, делая внутреннюю и открытую речь собственного производства доступной в концептуальной системе.
Все эти компоненты являются автономными специалистами по преобразованию входных данных в выходные. Между компонентами нет обратной связи или помех, что делает возможным возникновение речевых ошибок, потому что разные компоненты не видят, что во входных данных что-то не так.
Между компонентами нет обратной связи или помех, что делает возможным возникновение речевых ошибок, потому что разные компоненты не видят, что во входных данных что-то не так.
2.1 Теория слотов и наполнителей
Модель Левельта тесно связана с теорией слотов и наполнителей Стефани Шаттак-Хафнагель. Эта теория говорит о том, что при фонологическом кодировании существует три уровня обработки. Это морфологическое/метрическое изложение, сегментарное изложение и фонетическое изложение.
Теория слотов и заполнителей утверждает, что ошибки в словоформе возникают из-за сбоев в адресации. Подробно это говорит о том, что на каждом уровне устанавливаются различные структурные рамки, которые являются адресом для подходящих, самостоятельно написанных сублексических единиц. Эти кадры имеют слотов , которые могут быть заполнены соответствующими наполнителями , и каждый слот требует наполнителя своей категории. Эта теория «объясняет причинность ошибок сбоями двух процессов контроля: отбора и проверки» (уровень 19). 89, с. 351).
89, с. 351).
3 Виды речевых ошибок
В литературе упоминаются разные виды речевых ошибок, и в своей работе я приведу лишь некоторые из них. Глава 3 этой курсовой работы основана на Levelt (1989, страницы 214-223 и 330-351) и раздаточных материалах класса (дата: 27-01-03).
Типы речевых ошибок можно классифицировать с учетом используемых языковых единиц, например слог, морфема, фраза, слово и задействованные механизмы ошибок, например. смеси, замены, дополнения.
В следующей части я приведу примеры речевых ошибок и объясню, как они возникают. Я объясню следующие типы речевых ошибок: бленды, замены и обмены.
иллюстрация не видна в этом отрывке
Рисунок взят из: Levelt (1989, p.215)
В своей книге Levelt (1989) различает две причины речевых ошибок: концептуальное вторжение (рис. a и b) и ассоциативное вторжение (рисунок в и г). На приведенном выше рисунке C всегда обозначает предполагаемое понятие, а l — соответствующую лемму для этого понятия. Я расскажу об этом позже в своем тексте.
Я расскажу об этом позже в своем тексте.
3.1 Сочетания
3.1.1 Сочетания слов
Сочетания слов — это речевые ошибки, при которых два подходящих слова сливаются вместе и сливаются в одно слово, т. е. оба слова выбраны частично. «Извлекаются две леммы, которые конкурируют за один и тот же синтаксический слот» (Levelt 1989, стр. 215).
Мы различаем два вида сочетаний слов:
1) сочетания слов со сходным значением и 2) сочетания слов путем отвлечения внимания .
Пример первый тип :
— Irvine is совершенно ясно [близко/близко] (Fromkin 1973)
В этом классе словосочетаний два смешанных слова эквивалентны по значению и оба подходят в контексте предложения. Говорящий имеет в виду эти два взаимосвязанных понятия, и леммы для обоих слов активизируются почти одновременно. Затем оба лексических элемента извлекаются и вставляются в один и тот же слот поверхностной структуры, а слова смешиваются на уровне фонологической обработки. Поскольку два измененных слова очень похожи, мы говорим, что эти смешения произошли из-за концептуального вторжения (рис. 6.6а). Концептуальное вторжение происходит, когда «выбор леммы нарушается одновременной активностью двух или более понятий» (уровень 19).89, с. 214). Это происходит в Концептуализаторе, где выбирается соответствующая информация.
Поскольку два измененных слова очень похожи, мы говорим, что эти смешения произошли из-за концептуального вторжения (рис. 6.6а). Концептуальное вторжение происходит, когда «выбор леммы нарушается одновременной активностью двух или более понятий» (уровень 19).89, с. 214). Это происходит в Концептуализаторе, где выбирается соответствующая информация.
Пример второго типа :
— Dann sind aber Tatsachen zum Vorschwein [Vorschein/Schweinereien] gekommen (Meringer and Mayer 1895)
[…]
900 тип речевого дневника для мобильных устройств
Эксперимент — единственный метод исследования, который позволяет ученому установить причинно-следственную связь между независимой и зависимой переменной, но все еще многое можно узнать о человеческом поведении из естественных наблюдений. Действительно, именно в реальном мире человек часто наблюдает явление, которое интригует и увлекает этого человека, побуждая его или его выдвинуть гипотезу об этом явлении, а затем проверить эту гипотезу (часто с помощью эксперимента). Учитывая важную роль, которую натуралистическое наблюдение играет в научном методе, мы разработали свободно доступный инструмент, доступный через Интернет, чтобы побудить ученых-экспертов, ученых-стажеров и энтузиастов науки заниматься натуралистическим наблюдением за разговорной речью. акцентирование внимания на различных видах речевых ошибок. Этот веб-сайт собирает эти наблюдения и делает архив наблюдений доступным для дальнейшего анализа.
Учитывая важную роль, которую натуралистическое наблюдение играет в научном методе, мы разработали свободно доступный инструмент, доступный через Интернет, чтобы побудить ученых-экспертов, ученых-стажеров и энтузиастов науки заниматься натуралистическим наблюдением за разговорной речью. акцентирование внимания на различных видах речевых ошибок. Этот веб-сайт собирает эти наблюдения и делает архив наблюдений доступным для дальнейшего анализа.
Тщательная история области психолингвистики, о которой сообщается в Levelt (2013), показывает, что использование дневников для записи естественных наблюдений имеет долгую историю в изучении языкового развития . В произведении слов и звуков использование дневников, особенно коллекций речевых ошибок, таких как мальапропизмы и оговорки, со временем увеличивалось и уменьшалось, начиная с новаторской работы Мерингера и Мейера (1895 г.) , с периодическим возрождением использования дневников / сборников ошибок, появляющихся в работах Бумера и Лейвера, Катлера, Хоккета, Фромкина, Фрая, Маккея, Ноутебума, Шаттак-Хуфнагеля, Стембергера и других. Напротив, дневники и сборники ложных восприятий, известные как оговорки на слух , гораздо реже использовались при изучении речи восприятия ; работа Bond (1999) выделяется как один из немногих примеров использования этого подхода в течение нескольких десятилетий для изучения восприятия речи.
Напротив, дневники и сборники ложных восприятий, известные как оговорки на слух , гораздо реже использовались при изучении речи восприятия ; работа Bond (1999) выделяется как один из немногих примеров использования этого подхода в течение нескольких десятилетий для изучения восприятия речи.
Несмотря на важную роль, которую анализ ошибок может играть в теориях обработки речи, в области производства речи есть один класс моделей, который имеет тенденцию сосредотачиваться на хронометрических аспектах производства речи, а не на речевых ошибках (например, Levelt et al., 1999; но см. раздел 10 книги Levelt et al., 1999) и другой класс моделей, который имеет тенденцию сосредотачиваться на ошибках воспроизведения речи, а не на хронометрических аспектах производства речи (например, Dell, 1986, 1988; но см. Oppenheim et al., 2010). Что касается моделей распознавания устной речи, то ни одна из широко распространенных моделей не использовалась для учета ошибок восприятия/оговорок уха, хотя многие из этих моделей существуют уже несколько десятилетий, а некоторые претерпели значительные изменения в тот раз ( NAM : Luce and Pisoni, 1998; PARSYN : Luce et al. , 2000; Шорт-лист : Норрис, 1994; Норрис и МакКуин, 2008 г.; Когорта : Марслен-Уилсон, 1987; Гаскелл и Марслен-Уилсон, 1997 г.; TRACE : McClelland and Elman, 1986). Мы надеемся, что использование онлайн-дневника, описанного в данном отчете, приведет к существенным изменениям в общепринятых моделях языковой обработки в части учета различных типов речевых ошибок.
, 2000; Шорт-лист : Норрис, 1994; Норрис и МакКуин, 2008 г.; Когорта : Марслен-Уилсон, 1987; Гаскелл и Марслен-Уилсон, 1997 г.; TRACE : McClelland and Elman, 1986). Мы надеемся, что использование онлайн-дневника, описанного в данном отчете, приведет к существенным изменениям в общепринятых моделях языковой обработки в части учета различных типов речевых ошибок.
Ограничения восприятия или предубеждения наблюдателя часто вызывают опасения по поводу выводов, сделанных на основе совокупности естественных речевых ошибок. Тем не менее, в нескольких исследованиях сравнивались естественные ошибки и ошибки, выявленные с помощью различных методов в условиях контролируемой лаборатории, и было обнаружено близкое соответствие типов ошибок, наблюдаемых в этих двух условиях (например, Stemberger, 19).85). Таким образом, анализ речевых ошибок различных типов может обеспечить экологическую обоснованность наших теорий языковой обработки [например, Fay and Cutler, 1977; Витевич, 2002; Витевич и др. , 2014а; см. Lambert et al. (2010) для еще одного способа обеспечить экологическую обоснованность теорий языковой обработки], или, как напоминает нам Норман (1981, стр. 13): «Изучая ошибки, мы вынуждены демонстрировать, что наши теоретические идеи могут иметь некоторое отношение к реальным поведение.»
, 2014а; см. Lambert et al. (2010) для еще одного способа обеспечить экологическую обоснованность теорий языковой обработки], или, как напоминает нам Норман (1981, стр. 13): «Изучая ошибки, мы вынуждены демонстрировать, что наши теоретические идеи могут иметь некоторое отношение к реальным поведение.»
Более существенные проблемы использования дневников для накопления различного рода естественно возникающих речевых ошибок носят не практический характер. Во-первых, речевые ошибки встречаются «в природе» нечасто. Вейнен (1992) подсчитали, что взрослые могут совершить речевую ошибку один раз на каждую 1000 произнесенных слов, тогда как маленькие дети могут сделать от 4 до 8 речевых ошибок на каждую 1000 произнесенных слов. Использование лабораторных методов для вызова речи, таких как скороговорки (Shattuck-Hufnagel, 1992), Spoonerisms of Laboratory Induced Predisposition (SLIPs; Baars, 1992) или задания на выявление кончика языка (ToT) (Brown and McNeill, 1966). ) — также имеет тенденцию давать низкий уровень речевых ошибок.
Низкий уровень естественных речевых ошибок означает, что отдельный исследователь должен затратить значительное количество времени и усилий, чтобы собрать достаточно большую выборку речевых ошибок, чтобы можно было использовать статистический анализ. Например, Jaeger (2005) в течение 4 лет документировала речевые ошибки, допущенные ее тремя детьми. Напротив, некоторые лабораторные эксперименты по изучению других явлений у взрослых студенческого возраста могут быть завершены менее чем за 4 дня. Количество затрачиваемого времени и усилий не сильно уменьшится, если несколько участников вместо отдельного исследователя будут вести дневник речевых ошибок, с которыми они сталкиваются, как это было сделано для изучения состояний ToT (Burke et al., 19).91). Понятно, что накопление разного рода речевых ошибок требует много времени и усилий (иногда со стороны многих людей).
Учитывая время и усилия, которые требуются для сбора различных типов речевых ошибок, возможно, неудивительно, что дневники и другие сборники ошибок становятся почти собственностью и становятся доступными для других исследователей только после того, как основной исследователь тщательно изучил их. . Эта практика может привести к задержке от нескольких лет до десятилетий, прежде чем другие исследователи смогут изучить коллекции, предполагая, что коллекции вообще выпущены, а не потеряны из-за выхода на пенсию или смерти основного исследователя.
. Эта практика может привести к задержке от нескольких лет до десятилетий, прежде чем другие исследователи смогут изучить коллекции, предполагая, что коллекции вообще выпущены, а не потеряны из-за выхода на пенсию или смерти основного исследователя.
Если дневник или другой сборник ошибок предоставляется другим исследователям, необходимо учитывать ряд вопросов, связанных с долгосрочным хранением этих данных. Например, как описано по этому URL-адресу, http://www.mpi.nl/resources/data/fromkins-speech-error-database/fromkins-speech-error-database-background, скомпилированная база данных речевых ошибок (первоначально на бумаге карточки для заметок) Вики Фромкин несколько лет спустя был преобразован в компьютерно-читаемый формат. Однако этот формат программного обеспечения больше не получал технической поддержки, а это означало, что бесценный ресурс мог быть легко потерян. К счастью, Энн Катлер, Кэролайн Хентон, Питер Ладефогед, Зиб Нутбум, Карсон Шютце и Стефани Шаттак-Хафнагель при финансовой поддержке Общества Макса Планка организовали преобразование базы данных в формат XML. Процесс преобразования был выполнен Хансье Браамом под руководством Зиба Ноотебума, и результирующая база данных с возможностью поиска доступна на веб-странице Института психолингвистики Макса Планка 1 . Хотя база данных речевых ошибок Фромкина имеет счастливый конец, существует неизвестное количество других дневников и коллекций ошибок, которые не сохранились таким образом и были утеряны для будущих исследователей.
Процесс преобразования был выполнен Хансье Браамом под руководством Зиба Ноотебума, и результирующая база данных с возможностью поиска доступна на веб-странице Института психолингвистики Макса Планка 1 . Хотя база данных речевых ошибок Фромкина имеет счастливый конец, существует неизвестное количество других дневников и коллекций ошибок, которые не сохранились таким образом и были утеряны для будущих исследователей.
Курирование данных относится к сохранению того, что уже было собрано, но связанной с дневниками и другими коллекциями ошибок проблемой является их постоянный рост. Обычно дневники и сборники ошибок начинаются с определенной даты, а затем заканчиваются определенной датой (т. е. заранее установленным окончанием исследования или выходом на пенсию/смертью исследователя). Такие временные ограничения налагают ограничения на окончательный размер и препятствуют дальнейшему росту коллекции, что контрпродуктивно для статистического анализа, когда желательно иметь большие размеры выборки для удовлетворения различных статистических предположений.
Последнее, что нас беспокоит в отношении предыдущих дневников и других наборов ошибок, которые мы обсудим (хотя, безусловно, есть и другие), заключается в том, что они, как правило, были сосредоточены на определенной группе населения, например, на носителях определенного языка, которые были свободны от какой-либо речи, язык или нарушения слуха. Исключение лиц с нарушениями речи, языка или слуха (например, заикающихся или слабослышащих), лиц с когнитивными нарушениями или заболеваниями, такими как болезнь Альцгеймера, лиц, для которых данный язык не является родным, и т. д. имеет смысл. с методологической точки зрения, поскольку более однородная выборка уменьшает внешние источники изменчивости, которые могут скрывать небольшие, но теоретически важные различия. Однако подчинение этим методологическим соображениям приводит к некоторым непредвиденным последствиям. Например, исследование речевых ошибок в каждой из упомянутых выше популяций (а также кросс-лингвистических ошибок и ряда других областей) крайне мало представлено, что ограничивает наше понимание многих аспектов языковой обработки.
Чтобы решить некоторые из проблем, обсуждавшихся выше (и некоторые другие, которые мы опишем ниже), мы разработали метод, позволяющий людям документировать наблюдения трех распространенных типов естественных речевых ошибок (сделанных ими самими или другими)— оговорки, оговорки и состояния ToT — и для того, чтобы эти отдельные ошибки накапливались, архивировались и делались доступными для распространения. Оговорки (также известные как mondegreens ) относятся к ошибкам, при которых говорящий произносит слово или фразу правильно, но слушатель неправильно слышит сказанное (Бонд, 19).99). Напротив, оговорки включают ошибки, при которых говорящий намеревается сказать одно, но вместо этого произносит что-то другое (включая тип ошибки, известный как мальапропизм ). Оговорки включают (но не ограничиваются) замену одного слова или звука другим, замену звуков в соседних словах или смешение двух или более слов вместе. Наконец, состояние кончика языка относится к случаям, когда говорящий пытается извлечь известное слово из лексикона, но не может этого сделать. Говорящий может получить некоторую информацию о слове, например, его значение (например, «вещь, которую вы используете на подводной лодке, чтобы смотреть над водой»), первую букву или звук слова или другие слова, которые звучат как целевое слово (например, микроскоп, телескоп), но не предполагаемое слово (например, перископ).
Говорящий может получить некоторую информацию о слове, например, его значение (например, «вещь, которую вы используете на подводной лодке, чтобы смотреть над водой»), первую букву или звук слова или другие слова, которые звучат как целевое слово (например, микроскоп, телескоп), но не предполагаемое слово (например, перископ).
Существует множество других языковых ошибок, например, описки : ошибки при письме; промахи ключа : ошибки при наборе текста; промахи пальца : ошибки, сделанные на языках жестов, промахи точки : ошибки, сделанные при использовании шрифта Брайля (Wells-Jensen et al., 2007) и т. д., но инструмент, который мы разработали, в настоящее время фокусируется только на оговорках, оговорках и состояниях ToT. Если существующая база данных окажется успешной, возможно, в будущем ее можно будет расширить, включив в нее и другие типы ошибок. Кроме того, оговорки и другие типы речевых ошибок могут быть дополнительно классифицированы и подразделены. Мы не хотели навязывать другим исследователям какую-то конкретную теоретическую точку зрения, поэтому настоящий инструмент просто дает возможность накапливать ошибки; исследователи, загружающие архивы, несут ответственность за сортировку, классификацию и «очистку» собранных ошибок в соответствии с разработанными ими критериями.
Мы не хотели навязывать другим исследователям какую-то конкретную теоретическую точку зрения, поэтому настоящий инструмент просто дает возможность накапливать ошибки; исследователи, загружающие архивы, несут ответственность за сортировку, классификацию и «очистку» собранных ошибок в соответствии с разработанными ими критериями.
В дополнение к объединению трех типов речевых ошибок в одном ресурсе настоящее средство решает ряд проблем, описанных выше. Например, вместо отдельного исследователя, документирующего естественные ошибки, которые он или она наблюдает, или небольшой выборки участников, ведущих дневник в течение определенного периода времени, работа по документированию различных типов естественных речевых ошибок распределяется между всеми. пользователей онлайн-инструмента. «Краудсорсинг» документирование естественно возникающих речевых ошибок таким образом распределяет усилия между большим числом людей (вместо того, чтобы быть бременем одного исследователя), а также сокращает время, необходимое для получения большой выборки ошибок.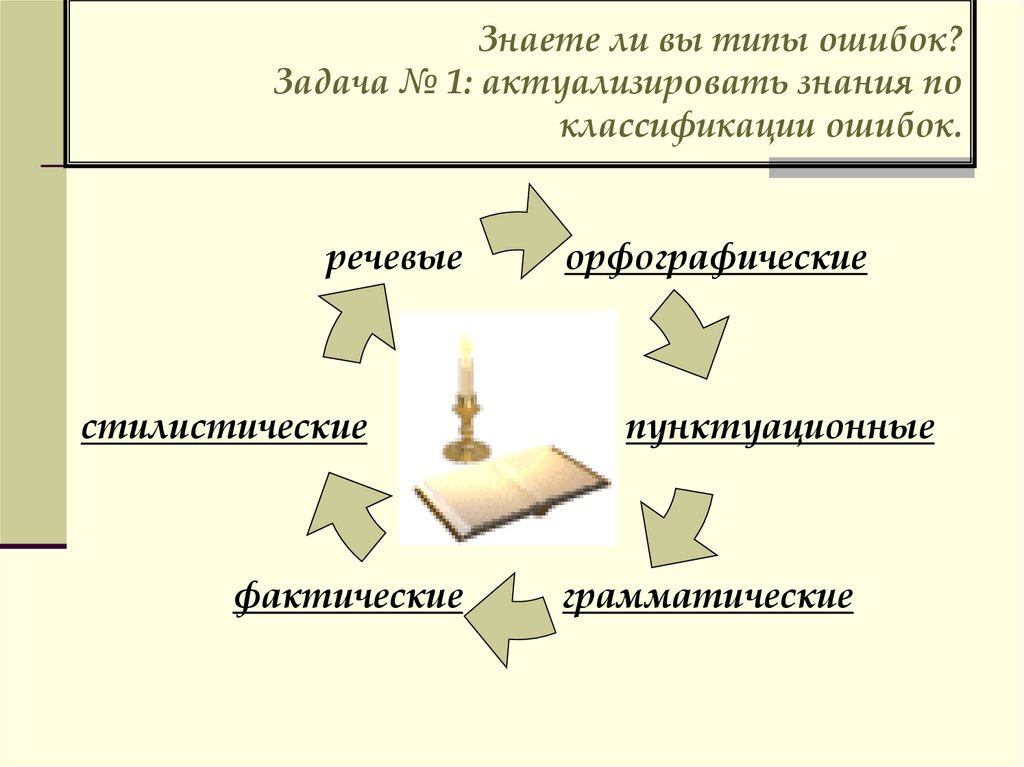 подходит для статистического анализа. Действительно, Dufau и соавт. (2011) использовали приложение для смартфона для сбора данных от более чем 4000 участников, расположенных по всему миру, за 4 месяца. Другие демонстрации скорости, эффективности и мощности этого подхода включают De Deyne et al. (2012) и Keuleers et al. (2015), в том числе.
подходит для статистического анализа. Действительно, Dufau и соавт. (2011) использовали приложение для смартфона для сбора данных от более чем 4000 участников, расположенных по всему миру, за 4 месяца. Другие демонстрации скорости, эффективности и мощности этого подхода включают De Deyne et al. (2012) и Keuleers et al. (2015), в том числе.
Что касается ограниченной доступности дневников и коллекций ошибок для других исследователей, задокументированные ошибки, собранные данным инструментом, будут доступны любому, кто создаст учетную запись на веб-сайте. Не нужно вносить свой вклад в сайт, чтобы получить доступ к ошибкам, которые были собраны другими. Вместо этого мы надеемся, что пользователи будут знакомы с проблемами, связанными с «безбилетниками» и «трагедией общего достояния», и сообщат о любых обнаруженных ими ошибках, если они загрузят и проанализируют ошибки, которые были собраны другими.
Описанный здесь онлайн-ресурс речевых ошибок также решает проблему ограничения предыдущих дневников по размеру и продолжительности периода сбора. Поскольку большое количество людей может вносить свой вклад в базу данных ошибок, существует вероятность накопления очень большого количества ошибок, даже если каждый человек вносит лишь небольшое количество ошибок. Кроме того, данные хранятся в текстовом формате, что делает их потенциально доступными в течение длительного времени (т. е. уменьшается беспокойство по поводу исчезновения поддержки определенного формата программного обеспечения). Более того, у коллекции есть большой потенциал для роста в течение очень длительного периода времени (и, возможно, она продолжит расти после того, как разработчики уйдут с поля и умрут). Непрерывный рост числа ошибок и большая продолжительность их возникновения открывают возможность для лонгитюдного анализа ошибок на большом количестве людей (ср. трое детей, изученных в Jaeger, 2005).
Поскольку большое количество людей может вносить свой вклад в базу данных ошибок, существует вероятность накопления очень большого количества ошибок, даже если каждый человек вносит лишь небольшое количество ошибок. Кроме того, данные хранятся в текстовом формате, что делает их потенциально доступными в течение длительного времени (т. е. уменьшается беспокойство по поводу исчезновения поддержки определенного формата программного обеспечения). Более того, у коллекции есть большой потенциал для роста в течение очень длительного периода времени (и, возможно, она продолжит расти после того, как разработчики уйдут с поля и умрут). Непрерывный рост числа ошибок и большая продолжительность их возникновения открывают возможность для лонгитюдного анализа ошибок на большом количестве людей (ср. трое детей, изученных в Jaeger, 2005).
В дополнение к документированию естественной речевой ошибки настоящий инструмент позволяет участникам включать другую соответствующую информацию, такую как наличие регионального диалекта, другого родного языка, нарушения речи, языка или слуха и т. д. Включение этой информации в сбор ошибок дает большему количеству исследователей возможность анализировать естественные речевые ошибки в ряде групп населения, которые реже изучаются в основных психолингвистических исследованиях, тем самым значительно расширяя наше понимание различных языковых процессов.
д. Включение этой информации в сбор ошибок дает большему количеству исследователей возможность анализировать естественные речевые ошибки в ряде групп населения, которые реже изучаются в основных психолингвистических исследованиях, тем самым значительно расширяя наше понимание различных языковых процессов.
Наконец, ученые-языковеды создали ряд онлайн-инструментов для лингвистов (например, Витевич и Люс, 2004; Сторкель и Гувер, 2010; Витевич и др., 2012). Мы, конечно же, надеемся, что данный инструмент окажется полезным для ученых-лингвистов в различных областях. Действительно, этот ресурс предлагает исследователям простой и быстрый способ проверить гипотезу, прежде чем тратить время и усилия на разработку и проведение полномасштабного эксперимента, а также средство для воспроизведения с экологически достоверными данными результатов, полученных в результате лабораторных экспериментов. (например, Витевич, 2002; Витевич и др., 2014а).
Однако мы также надеемся, что данный инструмент будет служить и более широкой, образовательной цели. Например, обычное домашнее задание на уроках психологии Advanced Placement (AP), которые преподаются в средних школах США, а также на уроках психологии языка или психолингвистики, которые преподаются в колледжах и университетах по всему миру, заключается в том, чтобы задокументировать какую-либо речевую ошибку. своего рода. Вместо того, чтобы помещать эти задания в буквальную или электронную корзину в конце семестра, эти индивидуальные задания класса можно было бы собрать с помощью настоящего инструмента (таким образом увеличив размер коллекции). Кроме того, ошибки, собранные на сегодняшний день, могут служить исходными данными, которые учащиеся в таких классах могут использовать для практики в классификации ошибок и проведении статистического анализа.
Например, обычное домашнее задание на уроках психологии Advanced Placement (AP), которые преподаются в средних школах США, а также на уроках психологии языка или психолингвистики, которые преподаются в колледжах и университетах по всему миру, заключается в том, чтобы задокументировать какую-либо речевую ошибку. своего рода. Вместо того, чтобы помещать эти задания в буквальную или электронную корзину в конце семестра, эти индивидуальные задания класса можно было бы собрать с помощью настоящего инструмента (таким образом увеличив размер коллекции). Кроме того, ошибки, собранные на сегодняшний день, могут служить исходными данными, которые учащиеся в таких классах могут использовать для практики в классификации ошибок и проведении статистического анализа.
Образовательный аспект настоящего инструмента также может выходить за рамки академического контекста, поощряя энтузиастов языка и ученых-граждан к участию в языковых исследованиях и дополнительно информируя широкую общественность о языковых исследованиях. Мы надеемся, что широкое использование онлайн-инструмента исследователями языка (например, лингвистами, логопедами, аудиологами, психологами, инженерами и т. энтузиастам будет проще сделать этот онлайн-инструмент бесплатным. Следующий раздел содержит дополнительные технические сведения об онлайн-инструменте, а также дополнительную информацию о типе собираемой информации.
Мы надеемся, что широкое использование онлайн-инструмента исследователями языка (например, лингвистами, логопедами, аудиологами, психологами, инженерами и т. энтузиастам будет проще сделать этот онлайн-инструмент бесплатным. Следующий раздел содержит дополнительные технические сведения об онлайн-инструменте, а также дополнительную информацию о типе собираемой информации.
Подробная информация о дневнике речевых ошибок (SpEDi)
Исследовательский центр Pew сообщил, что по состоянию на апрель 2015 г.: 64% взрослых американцев имеют смартфон, а 53% взрослых американцев владеют планшетным компьютером (интернет-проект Pew Research Center). опрос, 2015). Чтобы извлечь выгоду из повсеместного распространения этих мобильных устройств, мы решили разработать способ документирования естественных речевых ошибок, который можно было бы реализовать на этих вездесущих устройствах. Поскольку операционные системы различаются на разных устройствах, создание, поддержка и постоянное обновление приложения, которое пользователи могли бы загружать на самые разные устройства для документирования речевых ошибок, было бы непосильно с финансовой точки зрения.
Вместо этого мы разработали веб-сайт, который предлагал пользователям задавать ряд вопросов для документирования различных типов речевых ошибок. Поскольку дневник речевых ошибок находится в Интернете, пользователю не нужно загружать специальное программное обеспечение на свое устройство (рискуя заразиться компьютерным вирусом и т. д.), а также нам не нужно постоянно обновлять программное обеспечение, чтобы поддерживать его работоспособность с выпуском новую мобильную операционную систему или обновление. Чтобы упростить доступ к вопросам, можно создать ярлык браузера, чтобы перейти на страницу автоматического входа в систему (или для автоматического входа пользователя) на любом устройстве с веб-браузером, включая планшеты, мобильные/смартфоны, ноутбуки, настольные компьютеры и т. д. , Этот ярлык можно разместить на главном (или другом) экране мобильного устройства, тем самым создав впечатление, что SpEDi является собственным приложением, но при этом использует преимущества веб-приложения. Инструкции по добавлению ярлыков на веб-сайты на различных смартфонах и планшетах см. по адресу: http://www.howtogeek.com/19.6087/как добавить-веб-сайты на главный экран любого смартфона или планшета/
Инструкции по добавлению ярлыков на веб-сайты на различных смартфонах и планшетах см. по адресу: http://www.howtogeek.com/19.6087/как добавить-веб-сайты на главный экран любого смартфона или планшета/
Ниже мы используем снимки экрана, чтобы описать, как действовать в онлайн-дневнике речевых ошибок. . Как показано на панели (a) рисунка 1, URL-адрес http://spedi.ku.edu ведет пользователя на веб-страницу, с которой новые пользователи могут зарегистрироваться, а ранее зарегистрированные пользователи могут войти в систему. Новых пользователей запрашивают, см. панель (b) на рисунке 1, чтобы сгенерировать имя пользователя и пароль и предоставить свой адрес электронной почты и минимальную демографическую информацию, которая автоматически заполнит запись для любой речевой ошибки, которую они документируют сами (если зарегистрированный пользователь станет свидетелем речевой ошибки, сделанной кем-то в противном случае у зарегистрированного пользователя будет запрошена демографическая информация о говорящем, допустившем ошибку).
Рис. 1. (A) Начальная страница входа в онлайн-дневник речевых ошибок. (B) Информация, запрашиваемая у новых пользователей, регистрирующихся на сайте. (C) После ввода имени пользователя и пароля с помощью опции «Вход в учетную запись» зарегистрированный пользователь увидит подсказки, помогающие документировать различные типы речевых ошибок (в центре экрана; также доступно через «Опросник»). опция), а также опции «Загрузить данные» (т. е. ошибки, накопленные на сегодняшний день), отредактировать или обновить профиль пользователя (т. е. «Мой профиль») или «Выйти». (D) При использовании опции «Быстрый старт» зарегистрированный пользователь сразу переходит к сообщениям об ошибках речи. Обратите внимание на небольшую разницу в верхней левой части страницы при использовании опции «Быстрый старт» по сравнению с опцией «Вход в учетную запись» (см. рис. 1C).
Для ранее зарегистрированных пользователей есть два варианта входа. Возвращаясь к рисунку 1A, там есть опция «Быстрый старт» и опция «Вход в учетную запись». Для опции «Быстрый старт» необходимо ввести только зарегистрированное имя пользователя, что позволяет пользователю перейти непосредственно к подсказкам для документирования обнаруженной речевой ошибки (более подробно описано ниже). Для опции «Вход в учетную запись» необходимо ввести как имя пользователя, так и пароль. После этого пользователь увидит, как показано на рис. 1C, первые подсказки для документирования различных типов речевых ошибок и, что важно, также увидит (в верхней левой части страницы) опции для загрузки коллекции ошибок, собранных в свидание; доступ к базе данных могут получить только зарегистрированные пользователи через опцию «Вход в учетную запись».
Возвращаясь к рисунку 1A, там есть опция «Быстрый старт» и опция «Вход в учетную запись». Для опции «Быстрый старт» необходимо ввести только зарегистрированное имя пользователя, что позволяет пользователю перейти непосредственно к подсказкам для документирования обнаруженной речевой ошибки (более подробно описано ниже). Для опции «Вход в учетную запись» необходимо ввести как имя пользователя, так и пароль. После этого пользователь увидит, как показано на рис. 1C, первые подсказки для документирования различных типов речевых ошибок и, что важно, также увидит (в верхней левой части страницы) опции для загрузки коллекции ошибок, собранных в свидание; доступ к базе данных могут получить только зарегистрированные пользователи через опцию «Вход в учетную запись».
Опция «Быстрый старт» предназначена для быстрого перехода зарегистрированных пользователей к подсказкам об ошибках, что облегчает документирование речевой ошибки. Сравнивая рисунки 1C,D, читатель заметит небольшую разницу в верхней левой части страницы при использовании опции «Быстрый старт». Самое главное, накопившиеся на сегодняшний день ошибки нельзя загрузить при входе зарегистрированного пользователя на сайт через опцию «Быстрый старт», в противном случае подсказки для документирования речевой ошибки те же, и описаны ниже. Опять же, чтобы облегчить доступ к начальной странице дневника речевых ошибок, пользователь может использовать предпочитаемый веб-браузер, чтобы создать ярлык для страницы «Быстрый старт» и поместить ярлык на свой рабочий стол/планшет/телефон. Топ.
Самое главное, накопившиеся на сегодняшний день ошибки нельзя загрузить при входе зарегистрированного пользователя на сайт через опцию «Быстрый старт», в противном случае подсказки для документирования речевой ошибки те же, и описаны ниже. Опять же, чтобы облегчить доступ к начальной странице дневника речевых ошибок, пользователь может использовать предпочитаемый веб-браузер, чтобы создать ярлык для страницы «Быстрый старт» и поместить ярлык на свой рабочий стол/планшет/телефон. Топ.
Что-то УСЛЫШАНО неправильно
Когда происходит оговорка, то есть пользователь слышит что-то неправильно, или когда пользователь становится свидетелем того, как кто-то неправильно расслышал то, что было сказано правильно, следует нажать кнопку «Что-то УСЛЫШАНО неправильно». Это приводит пользователя к экрану, показанному на рисунке 2А, который предлагает пользователю ввести слова или фразы, которые были (неправильно) услышаны, а затем слова или фразы, которые были фактически (правильно) произнесены. Пользователя также просят указать, был ли он человеком, который неправильно расслышал слова или фразы, или же он был свидетелем неправильного расслышания; возможно, пользователь был человеком, который говорил правильно, но его собеседник неправильно расслышал сказанное, или пользователь был третьим лицом в группе, где произошла оговорка.
Пользователя также просят указать, был ли он человеком, который неправильно расслышал слова или фразы, или же он был свидетелем неправильного расслышания; возможно, пользователь был человеком, который говорил правильно, но его собеседник неправильно расслышал сказанное, или пользователь был третьим лицом в группе, где произошла оговорка.
Рис. 2. (A) Первый экран сообщения «Что-то СЛЫШНО неправильно». (B) Второй экран подсказки «Что-то УСЛЫШАНО неверно» и подсказки «Что-то СКАЗАЛ неправильно», запрашивающих у пользователя демографическую информацию о человеке, совершившем ошибку, которая была задокументирована на первом экране. (C) Третий экран подсказки «Что-то УСЛЫШАНО неправильно» и подсказки «Что-то СКАЗАЛ неправильно», запрашивая у пользователя демографическую информацию о человеке, совершившем ошибку, которая была задокументирована на первом экране. (D) Четвертый экран подсказки «Что-то УСЛЫШАНО неправильно» и подсказки «Что-то СКАЗАЛ неправильно», запрашивая у пользователя демографическую информацию о человеке, совершившем ошибку, которая была задокументирована на первом экране.
После того, как ошибка была задокументирована, пользователю предлагается ввести: приблизительный возраст говорящего на втором из четырех экранов (см. рис. 2Б) и информацию о поле и уровне образования говорящего на третьем из четыре экрана (см. рис. 2C). На финальном экране подсказок (см. рис. 2D) пользователя спрашивают: «Откуда они?» который предназначен для ненавязчивого получения информации, касающейся региональных диалектов (мы благодарим Зинни Бонд за предложение такого подхода), информации, касающейся речи, языка или слуха, а также вариантов любого другого типа когнитивного или неврологического расстройства, которые могут иметь место. как-то повлияло на ошибку. Существует также подсказка «Дополнительные примечания», где пользователь может задокументировать, что алкогольный напиток был выпит незадолго до совершения ошибки, что ошибка произошла в шумной обстановке или задокументировать любые другие факты, которые могут представлять интерес. Пользователю не требуется вводить информацию на экранах, изображенных на рисунках 2B-D, но по крайней мере часть этой информации будет полезна для других, анализирующих сбор ошибок в будущем.
Что-то СКАЗАЛ НЕПРАВИЛЬНО
Когда происходит оговорка, то есть пользователь говорит что-то неправильно, или когда пользователь становится свидетелем того, как кто-то другой говорит что-то неправильно, следует нажать кнопку «Что-то СКАЗАЛ неправильно». Это приводит пользователя к экрану, показанному на рис. 3, где пользователю предлагается ввести слова или фразы, которые были произнесены неправильно («Что было сказано на самом деле?»), а затем слова или фразы, которые предназначались (или которые говорящий спонтанно произнес в качестве исправления: «Что должно было быть сказано?»). Пользователя также просят указать, был ли он человеком, который неправильно произнес слова или фразы, или он был свидетелем того, как кто-то другой допустил ошибку. После того, как ошибка была задокументирована, пользователю предлагается ввести ту же демографическую информацию, которая появлялась в ответ на запрос «Что-то не так в SAID» (см. снова рисунки 2B–D).
Рисунок 3. Первый экран подсказки «Что-то SAID неправильно» .
Первый экран подсказки «Что-то SAID неправильно» .
Пытается думать о слове, но не может его вспомнить
В состоянии ToT человек пытается вспомнить слово или имя человека, место, книгу или фильм, но не может. Часто человек может получить некоторую информацию о слове или имени, например, первую букву или звук слова или имени, количество слогов в слове или имени, а иногда слова или имена, которые звучат похоже на цель. слово или имя. Браун и Макнил (1966) разработал метод выявления состояний ToT в лаборатории, дав участникам определение и попросив их назвать наиболее подходящее слово; этот подход успешно использовался рядом исследователей для изучения различных вопросов (Harley and Bown, 1998; James and Burke, 2000; Vitevitch and Sommers, 2003). Состояния ToT также были задокументированы в дневниковых исследованиях, в которых участники записывали подробности о каждом проявлении состояния ToT (Burke et al., 1991). Чтобы сохранить некоторую преемственность с предыдущими дневниковыми исследованиями, мы адаптировали подсказки, использованные в Burke et al. (1991; доступен по адресу http://www.lcs.pomona.edu/cogaging/materials/research/TOT%20diary.pdf) для настоящего онлайн-дневника ошибок.
(1991; доступен по адресу http://www.lcs.pomona.edu/cogaging/materials/research/TOT%20diary.pdf) для настоящего онлайн-дневника ошибок.
На первом экране подсказки ToT пользователю предлагается указать, какой тип слова не может быть вызван (рис. 4А). Второй экран запрашивает субъективную оценку по 7-балльной шкале «Насколько вы уверены, что это слово вам знакомо?» (Рисунок 4Б). На втором и последующих экранах пользователи могут вводить столько информации, сколько они помнят (или хотят ввести), прежде чем перейти к следующему экрану. Третий экран запрашивает субъективную оценку по 7-балльной шкале «Насколько вы уверены, что сможете вспомнить это слово?» (Рисунок 4С). Четвертый экран спрашивает пользователя, может ли он вспомнить какие-либо характеристики слова, которое он пытается вспомнить, например, количество слогов, первый звук, с которого оно начинается, и т. д.; здесь можно проверить несколько вариантов (рис. 4D). На пятом экране пользователя просят предоставить любую дополнительную информацию, которую он может придумать о слове, которое он пытается вспомнить (рис. 4E).
4E).
Рис. 4. (A) Первый экран подсказки ToT, запрашивающей информацию о типе слова, которое невозможно вспомнить. (B) Второй экран подсказки ToT, запрашивающей информацию о типе слова, которое невозможно вспомнить. (C) Третий экран подсказки ToT с запросом информации о типе слова, которое нельзя вспомнить. (D) Четвертый экран подсказки ToT с запросом информации о типе слова, которое невозможно вспомнить (E) Пятый экран подсказки ToT с запросом информации о типе слова, которое невозможно вспомнить.
На шестом экране (рис. 5А) пользователя просят ввести любые посторонние или похожие по звучанию слова, которые приходят на ум вместо целевого слова. Седьмой экран (рис. 5B) спрашивает пользователя, какие стратегии он мог использовать, чтобы вспомнить имя или слово, например, спрашивая друга или консультируясь в Интернете. Другие стратегии, которые может использовать пользователь, задаются на восьмой странице (рис. 5C). На девятом экране пользователя спрашивают, как ему наконец удалось отозвать работу (если состояние ToT было успешно разрешено). Их также просят оценить количество времени, прошедшее между первоначальной попыткой получить слово или имя и разрешением состояния ToT (рис. 5D). После разрешения ToT на последнем экране (рис. 5E) у пользователя запрашивается слово или имя, которые вызвали начальное состояние ToT.
5C). На девятом экране пользователя спрашивают, как ему наконец удалось отозвать работу (если состояние ToT было успешно разрешено). Их также просят оценить количество времени, прошедшее между первоначальной попыткой получить слово или имя и разрешением состояния ToT (рис. 5D). После разрешения ToT на последнем экране (рис. 5E) у пользователя запрашивается слово или имя, которые вызвали начальное состояние ToT.
Рис. 5. (A) Шестой экран подсказки ToT, запрашивающей информацию о типе слова, которое невозможно вспомнить. (B) Седьмой экран подсказки ToT, запрашивающей информацию о типе слова, которое невозможно вспомнить. (C) Восьмой экран подсказки ToT с запросом информации о типе слова, которое невозможно вспомнить. (D) Девятый экран подсказки ToT, запрашивающей информацию о типе слова, которое невозможно вспомнить. (E) Последний экран подсказки ToT с запросом информации о типе слова, которое невозможно вспомнить.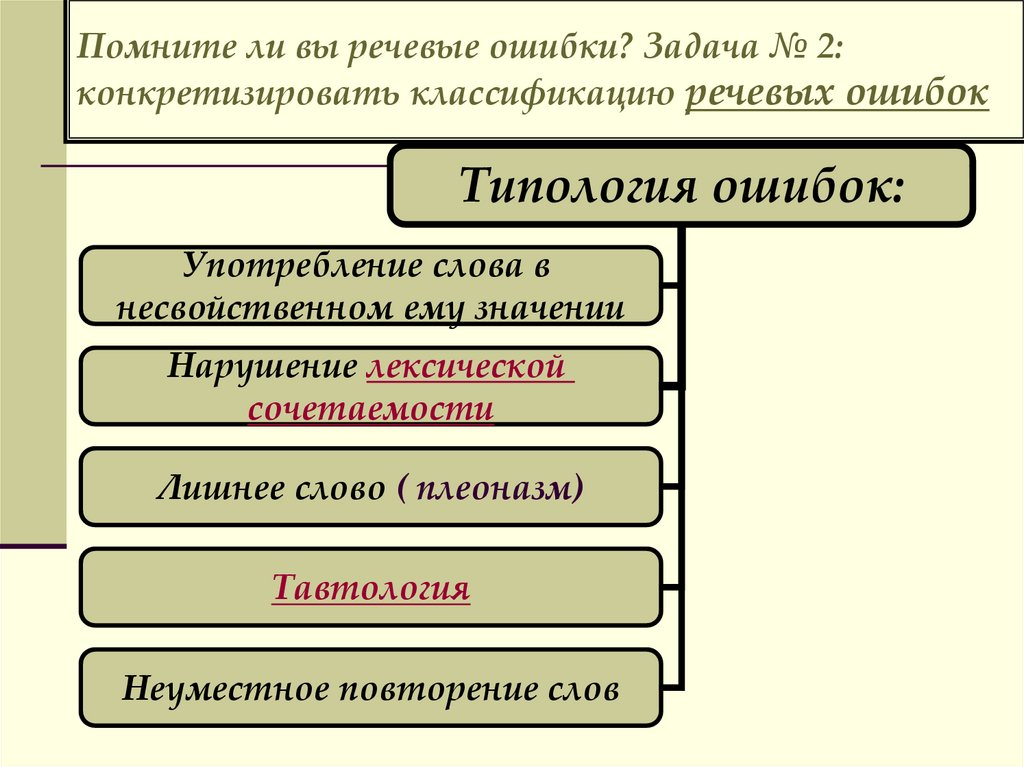
Загрузка данных
Вся информация, введенная в подсказках онлайн-дневника речевых ошибок (см. рис. 2А и 5Е), сохраняется в текстовом файле с разделителями-запятыми (CSV). Этот текстовый файл можно загрузить после того, как зарегистрированный пользователь введет имя своей учетной записи и пароль, используя опцию «Вход в учетную запись». Напомним, что опция «Быстрый старт» предназначена для быстрого перехода зарегистрированных пользователей к подсказкам об ошибках для облегчения документирования речевой ошибки; к собранным ошибкам нельзя получить доступ с помощью опции «Быстрый старт».
Информация, представленная в файле данных, необработана и никак не обрабатывается. Исследователям рекомендуется использовать доступное программное обеспечение для работы с электронными таблицами, программное обеспечение для обработки текстов или специально написанные сценарии или программное обеспечение для облегчения первоначальной и последующей обработки необработанных данных. Мы не реализовывали какие-либо функции поиска или сортировки на веб-сайте, поскольку не хотели навязывать определенную теоретическую точку зрения другим пользователям, которые могут захотеть проанализировать данные с новой или альтернативной теоретической точки зрения. Хотя необработанный характер данных требует некоторой работы со стороны исследователя для их анализа, необработанный характер данных обеспечивает долговечность накопленных данных по мере того, как теоретические перспективы приходят и уходят с течением времени.
Хотя необработанный характер данных требует некоторой работы со стороны исследователя для их анализа, необработанный характер данных обеспечивает долговечность накопленных данных по мере того, как теоретические перспективы приходят и уходят с течением времени.
Ограничения SpEDi
Настоящий онлайн-дневник речевых ошибок ограничен теми же проблемами, предубеждениями и опасениями, которые ограничивают все формы натуралистического наблюдения, включая сборники речевых ошибок и дневники (см. и др., 2016). Несмотря на эти общие ограничения, мы считаем, что нынешний онлайн-дневник речевых ошибок по-прежнему имеет большую научную и образовательную ценность.
Путем «краудсорсинга» сбора различных типов речевых ошибок мы потенциально ускорили темп накопления достаточно большого количества ошибок, чтобы подвергнуть их статистическому анализу. Однако «краудсорсинг» сбора ошибок открывает процесс для участников, у которых может не быть даже базовой подготовки в области лингвистики и других наук, связанных с языком. Это означает, что тонкие ошибки воспроизведения речи, такие как воспроизведение фонетической особенности, которой нет в родном языке, могут остаться незамеченными или недокументированными, или быть задокументированы неправильно. Хотя этот аспект интерактивного дневника речевых ошибок может внести или увеличить вариативность ответов, мы надеемся, что обработка данных, проведенная исследователями (удаление выбросов и т. д.), и большое количество ошибок, накопленных с течением времени, обеспечат необходимая статистическая стабильность, позволяющая исследователям наблюдать новые и интересные закономерности в данных.
Это означает, что тонкие ошибки воспроизведения речи, такие как воспроизведение фонетической особенности, которой нет в родном языке, могут остаться незамеченными или недокументированными, или быть задокументированы неправильно. Хотя этот аспект интерактивного дневника речевых ошибок может внести или увеличить вариативность ответов, мы надеемся, что обработка данных, проведенная исследователями (удаление выбросов и т. д.), и большое количество ошибок, накопленных с течением времени, обеспечат необходимая статистическая стабильность, позволяющая исследователям наблюдать новые и интересные закономерности в данных.
Другим ограничением SpEDi является то, что подсказки для получения информации представлены на английском языке, что может ограничить использование дневника ошибок англоговорящими людьми. Мы понимаем, что для перевода подсказок на веб-страницах можно использовать такие инструменты, как Google Translate; к сожалению, мы не можем проверить точность таких переводов. Использование английского языка в подсказках несколько симптоматично для более серьезной проблемы в психолингвистических исследованиях, а именно, большая часть исследований посвящена английскому языку и посвящена ему (Vitevitch et al. , 2014b). Несомненно, многое можно понять о механизмах, связанных с различными аспектами языковой обработки, которые можно получить, изучая языки, отличные от английского, или изучая использование более чем одного языка одновременно. К счастью, дневник ошибок позволяет пользователям вводить информацию, используя любой символ, который может быть воспроизведен с помощью клавиатуры, что позволяет пользователям логографических, слоговых и буквенных орфографий сообщать (по крайней мере, о некоторых типах) речевых ошибок, если их клавиатура настроена на их шрифт. выбора. Это также открывает возможность для лингвистически искушенных пользователей использовать символы из Международного фонетического алфавита (IPA) для документирования более мелких ошибок с помощью фонологической транскрипции.
, 2014b). Несомненно, многое можно понять о механизмах, связанных с различными аспектами языковой обработки, которые можно получить, изучая языки, отличные от английского, или изучая использование более чем одного языка одновременно. К счастью, дневник ошибок позволяет пользователям вводить информацию, используя любой символ, который может быть воспроизведен с помощью клавиатуры, что позволяет пользователям логографических, слоговых и буквенных орфографий сообщать (по крайней мере, о некоторых типах) речевых ошибок, если их клавиатура настроена на их шрифт. выбора. Это также открывает возможность для лингвистически искушенных пользователей использовать символы из Международного фонетического алфавита (IPA) для документирования более мелких ошибок с помощью фонологической транскрипции.
Наконец, SpEDi позволяет документировать только три типа речевых ошибок: оговорки/малапропизмы, оговорки и состояния ToT. Существуют и другие типы ошибок, связанных с языком, такие как оплошность ключа и оплошность пальца, которые совершают пользователи языка, но текущая форма SpEDi не предлагает пользователям подсказок документировать эти другие типы ошибок, связанных с языком. . Существуют и другие типы двигательных или исполнительных ошибок, которые совершают люди, например, когда человек лезет в кухонный ящик, чтобы достать нож, но вместо этого ошибочно достает ложку, которые текущая форма SpEDi не предлагает пользователям для документирования. Можно было бы получить более широкое представление о познании, если бы такие двигательные/исполнительные ошибки рассматривались наряду с речевыми ошибками. Возможно, некоторые из ограничений SpEDi можно устранить, увеличив финансовую поддержку за счет краудфандинга для поддержки более поздних этапов разработки SpEDi. Несмотря на эти ограничения, мы считаем, что онлайн-дневник речевых ошибок окажется полезным инструментом для исследований, связанных с языком, и для научных усилий по распространению информации.
. Существуют и другие типы двигательных или исполнительных ошибок, которые совершают люди, например, когда человек лезет в кухонный ящик, чтобы достать нож, но вместо этого ошибочно достает ложку, которые текущая форма SpEDi не предлагает пользователям для документирования. Можно было бы получить более широкое представление о познании, если бы такие двигательные/исполнительные ошибки рассматривались наряду с речевыми ошибками. Возможно, некоторые из ограничений SpEDi можно устранить, увеличив финансовую поддержку за счет краудфандинга для поддержки более поздних этапов разработки SpEDi. Несмотря на эти ограничения, мы считаем, что онлайн-дневник речевых ошибок окажется полезным инструментом для исследований, связанных с языком, и для научных усилий по распространению информации.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Благодарности
Мы хотим поблагодарить Zinny Bond, Debbie Burke, Susan Kemper и Thomas Dellecave за полезные обсуждения и предложения относительно языковых дневников и коллекций ошибок, а также за разъяснения вопросов, связанных с реализацией. Этот проект был частично поддержан Фондом общих исследований поведенческих наук Канзасского университета. 9 http://www.mpi.nl/dbmpi/cgi-bin/sedb/sperco_form4.pl
Ссылки
Баарс, Б. Дж. (1992). «Дюжина методов конкурирующих планов для вызывания предсказуемых оговорок в речи и действиях», в Experimental Slips and Human Error: Exploring the Architecture of Volition , ed. Б. Дж. Баарс (Нью-Йорк, штат Нью-Йорк: Plenum Press), 129–150.
Google Scholar
Bond, ZS (1999). Оговорки: ошибки в восприятии случайного разговора . Нью-Йорк: Академическая пресса.
Google Scholar
Браун Р. и Макнил Д. (1966). Феномен «кончика языка». J. Глагол. Учиться. Глагол. Поведение 5, 325–337. doi: 10.1016/S0022-5371(66)80040-3
Поведение 5, 325–337. doi: 10.1016/S0022-5371(66)80040-3
Полный текст CrossRef | Google Scholar
Берк Д.М., Маккей Д.Г., Уортли Дж.С. и Уэйд Э. (1991). На кончике языка: что вызывает проблемы с подбором слов у молодых и пожилых людей? Дж. Мем. Ланг. 30, 542–579. дои: 10.1016/0749-596X(91)-G
Полнотекстовая перекрестная ссылка | Google Scholar
Де Дейн С., Наварро Д. и Стормс Г. (2012). Лучшее объяснение лексического и семантического познания с использованием сетей, полученных из продолжительных, а не из отдельных словесных ассоциаций. Поведение. Рез. Методы 45, 480–498. doi: 10.3758/s13428-012-0260-7
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Делл, Г. С. (1986). Теория распространения-активации поиска в производстве предложений. Психология. Ред. 93, 283–321. doi: 10.1037/0033-295X.93.3.283
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Делл, Г. С. (1988). Поиск фонологических форм в производстве: проверка предсказаний коннекционистской модели. Дж. Мем. Ланг. 27, 124–142. doi: 10.1016/0749-596X(88)
С. (1988). Поиск фонологических форм в производстве: проверка предсказаний коннекционистской модели. Дж. Мем. Ланг. 27, 124–142. doi: 10.1016/0749-596X(88)
-8
Полный текст CrossRef | Google Scholar
Dufau, S., Duñabeitia, J.A., Moret-Tatay, C., McGonigal, A., Peeters, D., and Alario, F.-X, et al. (2011). Смартфон, умная наука: как использование смартфонов может революционизировать исследования в области когнитивистики. ПЛОС ОДИН 6:e24974. doi: 10.1371/journal.pone.0024974
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Фэй Д. и Катлер А. (1977). Малапропизмы и структура мысленного лексикона. Лингвист. Инк. 8, 505–520.
Google Scholar
Гаскелл, М. Г., и Марслен-Уилсон, В. Д. (1997). Интеграция формы и значения: распределенная модель восприятия речи. Ланг. Познан. проц. 12, 613–656. дои: 10.1080/0167386646
CrossRef Полный текст | Google Scholar
Harley, TA, and Bown, HE (1998). Что вызывает состояние кончика языка? Доказательства эффектов лексического соседства в речевом производстве. Бр. Дж. Психол. 89, 151–174. doi: 10.1111/j.2044-8295.1998.tb02677.x
Что вызывает состояние кончика языка? Доказательства эффектов лексического соседства в речевом производстве. Бр. Дж. Психол. 89, 151–174. doi: 10.1111/j.2044-8295.1998.tb02677.x
Полный текст CrossRef | Google Scholar
Jaeger, JJ (2005). Детские оговорки: что рассказывают маленькие дети о языковых оговорках . Махва, Нью-Джерси: Лоуренс Эрлбаум.
Google Scholar
Джеймс, Л. Э., и Берк, Д. М. (2000). Влияние фонологического прайминга на поиск слов и ощущения кончика языка у молодых и пожилых людей. Дж. Экспл. Психол. 26, 1378–1391. doi: 10.1037/0278-7393.26.6.1378
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Keuleers, E., Stevens, M., Mandera, P., and Brysbaert, M. (2015). Знание слов в толпе: измерение размера словарного запаса и распространенности слов в масштабном онлайн-эксперименте. Q. J. Exp. Психол. 68, 1665–1692. doi: 10.1080/17470218.2015.1022560
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ламберт Б. Л., Дики Л. В., Фишер В. М., Гиббонс Р. Д., Лин С. Дж., Люс П. А. и др. (2010). Слушайте внимательно: риск ошибки в устных приказах о лекарствах. Соц. науч. Мед. 70, 1599–1608. doi: 10.1016/j.socscimed.2010.01.042
Л., Дики Л. В., Фишер В. М., Гиббонс Р. Д., Лин С. Дж., Люс П. А. и др. (2010). Слушайте внимательно: риск ошибки в устных приказах о лекарствах. Соц. науч. Мед. 70, 1599–1608. doi: 10.1016/j.socscimed.2010.01.042
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Levelt, WJM (2013). История психолингвистики: дохомская эпоха . Оксфорд: Издательство Оксфордского университета.
Google Scholar
Levelt, WJM, Roelofs, A., and Meyer, A.S. (1999). Теория лексического доступа в речевом производстве. Поведение. наук о мозге. 22, 1–75. doi: 10.1017/S0140525X976
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Люс П.А., Голдингер С.Д., Ауэр Э.Т. мл. и Витевич М.С. (2000). Фонетический прайминг, активация соседства и PARSYN. Восприятие. Психофиз. 62, 615–625. doi: 10.3758/BF03212113
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Люс П.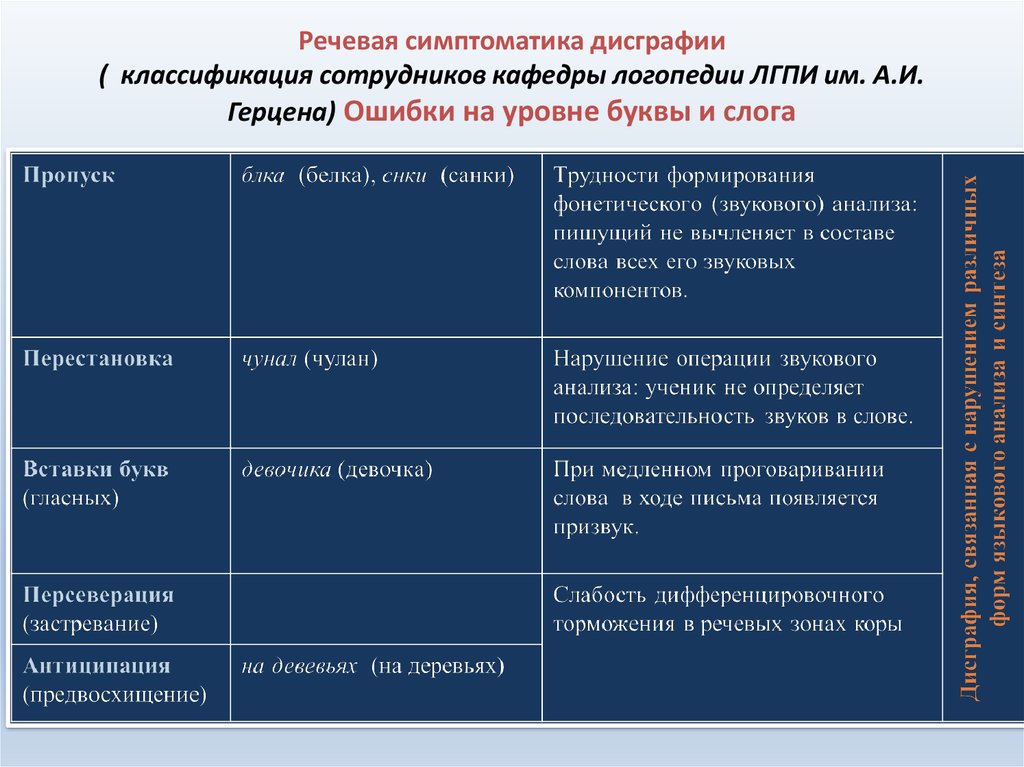 А. и Пизони Д.Б. (1998). Распознавание произносимых слов: модель активации соседства. Ухо Слушай 19, 1–36. doi: 10.1097/00003446-199802000-00001
А. и Пизони Д.Б. (1998). Распознавание произносимых слов: модель активации соседства. Ухо Слушай 19, 1–36. doi: 10.1097/00003446-199802000-00001
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Marslen-Wilson, WD (1987). Функциональный параллелизм в устном распознавании слов. Познание 25, 71–102. doi: 10.1016/0010-0277(87)
-9
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Макклелланд, Дж. Л., и Элман, Дж. Л. (1986). Модель восприятия речи TRACE. Познан. Психол. 18, 1–86. doi: 10.1016/0010-0285(86)-0
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Меринджер М. и Мейер К. (1895 г.). Versprechen und Verlesen: Eine Psychologisch-linguistische Studie . Штутгарт: GJ Göschen’sche Verlagshandung, редакторы А. Катлер и Д. А. Фэй (Амстердам: Дж. Бенджаминс).
Google Scholar
Норман, Д. А. (1981). Категоризация пропусков действий. Психология. Ред. 88, 1–15. doi: 10.1037/0033-295X.88.1.1
Психология. Ред. 88, 1–15. doi: 10.1037/0033-295X.88.1.1
Полный текст CrossRef | Google Scholar
Норрис, Д. (1994). Краткий список: коннекционистская модель непрерывного распознавания речи. Познание 52, 189–234. doi: 10.1016/0010-0277(94)-4
Полный текст CrossRef | Google Scholar
Норрис, Д., и Маккуин, Дж. М. (2008). Список B: байесовская модель непрерывного распознавания речи. Психология. Ред. 115, 357–395. doi: 10.1037/0033-295X.115.2.357
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Оппенгейм, Г. М., Делл, Г. С., и Шварц, М. Ф. (2010). Темная сторона постепенного обучения: модель кумулятивной семантической интерференции во время лексического доступа при производстве речи. Познание 114, 227–252. doi: 10.1016/j.cognition.2009.09.007
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Исследование интернет-проектов Pew Research Center (2015 г. ). «Различие смартфонов» Доступно по ссылке: http://www.pewinternet.org/2015/04/01/us-smartphone-use-in-2015/
). «Различие смартфонов» Доступно по ссылке: http://www.pewinternet.org/2015/04/01/us-smartphone-use-in-2015/
Google Scholar
Шаттак-Хуфнагель, С. (1992). Роль структуры слова в сегментарном последовательном порядке. Познание 42, 213–259. doi: 10.1016/0010-0277(92)
-I
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Stemberger, JP (1985). «Надежность и воспроизводимость данных о естественных ошибках речи: сравнение с экспериментально вызванными ошибками», в Experimental Slips and Human Error: Exploring the Architecture of Volition , изд. Б. Дж. Баарс (Нью-Йорк: Plenum Press), 195–215.
Google Scholar
Сторкель, Х.Л., и Гувер, Дж.Р. (2010). Онлайн-калькулятор для расчета фонотактической вероятности и плотности соседства на основе дочерних корпусов разговорного американского английского. Поведение. Рез. Методы 42, 497–506. doi: 10.3758/BRM.42.2.497
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Витевич М. С. (2002). Натуралистический и экспериментальный анализ эффектов частоты слов и плотности соседства в слуховых оговорках. Ланг. Речь 45, 407–434. doi: 10.1177/0023830
С. (2002). Натуралистический и экспериментальный анализ эффектов частоты слов и плотности соседства в слуховых оговорках. Ланг. Речь 45, 407–434. doi: 10.1177/0023830
50040501
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Витевич М.С., Чан К.Ю. и Гольдштейн Р. (2014a). Взгляд на неудачный лексический поиск из сетевой науки. Познан. Психол. 68, 1–32. doi: 10.1016/j.cogpsych.2013.10.002
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Витевич М.С., Чан К.Ю. и Гольдштейн Р. (2014b). «Использование английского языка в качестве «образцового языка» для понимания языковой обработки», в Нарушения моторной речи. Межъязыковая перспектива , ред. Н. Миллер и А. Лоуит (Бристоль: вопросы многоязычия), 58–73.
Google Scholar
Витевич М.С., Гольдштейн Р. и Джонсон Э. (2016). «Длина пути и неправильное восприятие речи: выводы из сетевой науки и психолингвистики», в «На пути к теоретической основе для анализа сложных лингвистических сетей », редакторы А.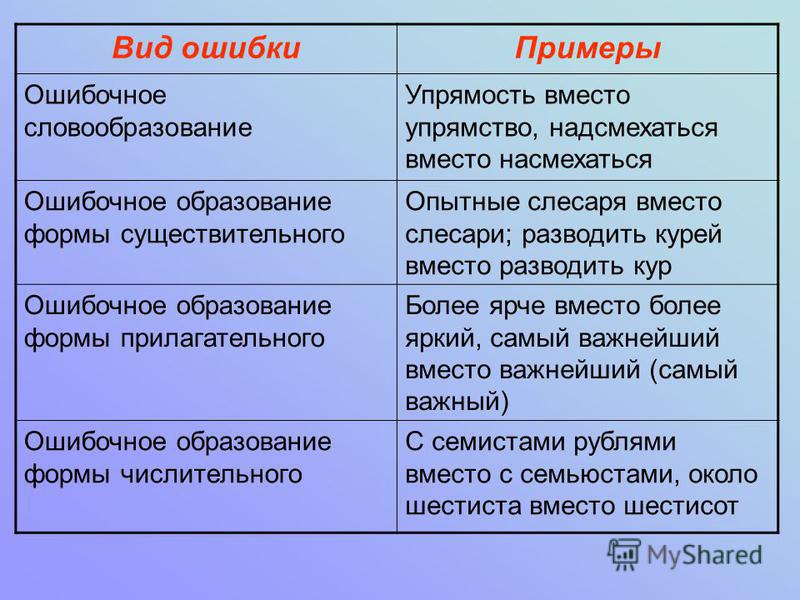 Мелер, А. Люкинг, С. Баниш, П. Бланшар и Б. Франк-Джоб (Берлин: Understanding Complex Systems, Springer), 29–45. doi: 10.1007/978-3-662-47238-5
Мелер, А. Люкинг, С. Баниш, П. Бланшар и Б. Франк-Джоб (Берлин: Understanding Complex Systems, Springer), 29–45. doi: 10.1007/978-3-662-47238-5
Полный текст CrossRef | Google Scholar
Витевич, М.С., и Люс, П.А. (2004). Веб-интерфейс для расчета фонотактической вероятности для слов и не слов на английском языке. Поведение. Рез. Методы Инструм. вычисл. 36, 481–487. doi: 10.3758/BF03195594
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Витевич М.С. и Соммерс М.С. (2003). Облегчающее влияние фонологического сходства и частоты соседства на речеобразование у молодых и пожилых людей. Мем. Познан. 31, 491–504. doi: 10.3758/BF03196091
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Витевич М.С., Стамер М.К. и Кивег Д. (2012). The Beginning Spanish Lexicon: веб-интерфейс для расчета фонологического сходства среди испанских слов у взрослых, изучающих испанский язык как иностранный. Второй язык. Рез. 28, 103–112. doi: 10.1177/0267658311432199
Рез. 28, 103–112. doi: 10.1177/0267658311432199
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Уэллс-Дженсен С., Шварц А. и Гоше Б. (2007). Когнитивный подход к ошибкам Брайля. Дж. Виз. Обесценить. Слепой. 101, 416–428.
Google Scholar
Wijnen, F. (1992). Случайные словесные и звуковые ошибки у молодых ораторов. Дж. Мем. Ланг. 31, 734–755. doi: 10.1016/0749-596X(92)
-X
Полный текст CrossRef | Google Scholar
Что такое речевая ошибка? (с картинками)
`;
Эндрю Кирмайер
Ошибка речи возникает, когда кто-то произносит слова или звуки, которые он не собирался произносить. Оговорки распространены в повседневной речи и часто следуют общим схемам манипулирования конкретными грамматическими конструкциями. Общие типы проскальзывания включают мальапропизмы, метатезис или эпентезис. Обычно это нормально, но они могут возникать чаще, если присутствуют такие состояния, как дислексия или проблемы с движением глаз или контролем мышц.
Оговорки распространены в повседневной речи и часто следуют общим схемам манипулирования конкретными грамматическими конструкциями. Общие типы проскальзывания включают мальапропизмы, метатезис или эпентезис. Обычно это нормально, но они могут возникать чаще, если присутствуют такие состояния, как дислексия или проблемы с движением глаз или контролем мышц.
Человеческая речь широко изучалась как в реальных условиях, так и в лабораториях. Различные части речи более очевидны, когда возникает и анализируется речевая ошибка. При малапропизме произносится слово, которое не предназначено для произнесения, но обычно либо похоже по смыслу на то, что человек хотел сказать, либо звучит очень похоже на него. Люди также часто меняют слоги в словах или меняют местами слова в конкретном предложении, что называется метатезисом. Эпентезис относится к добавлению звуков к середине или концу слов.
Люди также часто меняют слоги в словах или меняют местами слова в конкретном предложении, что называется метатезисом. Эпентезис относится к добавлению звуков к середине или концу слов.
Возникновение речевых ошибок может быть результатом различий в движении между частями языка, а также скорости, с которой они двигаются вместе или по отношению друг к другу. В большинстве случаев гласные заменяются только гласными, и то же самое касается согласных. Слова чаще всего заменяются другими, подходящими к аналогичному грамматическому контексту. Сильная закономерность, наблюдаемая при языковой патологии, заключается в том, что слова и звуки перемещаются друг на друга, а не удаляются из общей фразы.
Мышечные движения и время реакции, а также скорость речи оказывают существенное влияние на каждую возникающую речевую ошибку. Повторение движений языка, губ и челюсти взаимосвязано с фонологическим сходством многих звуков и слов. Речевые ошибки не случайны и изучались в патологии речи для создания различных языковых моделей.
Когда людям трудно контролировать движения глаз, это может повлиять на то, как они читают. Проблемы с движением головы также имеют место, и это приводит к форме дислексии, которая может повлиять на речь. Такие состояния, как болезнь Паркинсона, также могут привести к проблемам с речевой патологией. Неспособность к обучению и клинические проблемы с поиском слов, которые могут возникнуть в результате травм, могут увеличить частоту речевых ошибок. Оговорки обычно не являются признаком речевого расстройства, связанного с афазией; они случаются со всеми в какой-то момент.
Проблемы с движением головы также имеют место, и это приводит к форме дислексии, которая может повлиять на речь. Такие состояния, как болезнь Паркинсона, также могут привести к проблемам с речевой патологией. Неспособность к обучению и клинические проблемы с поиском слов, которые могут возникнуть в результате травм, могут увеличить частоту речевых ошибок. Оговорки обычно не являются признаком речевого расстройства, связанного с афазией; они случаются со всеми в какой-то момент.
Онлайн-инструмент позволяет публике отслеживать состояния «на кончике языка», речевые ошибки
Ср, 05. 08.2015
08.2015
ЛОУРЕНС — Мы все были там. Иногда в разгар разговора в голове вспыхивает пустота, и невозможно подобрать слово для обозначения вещи, места или человека. Мы будем жестикулировать руками и чувствовать, что вот-вот вспомним. Но слова не будет.
Это затруднительное состояние, которое исследователи языка называют «состоянием кончика языка».
«Эти состояния интересны по нескольким причинам, — сказал Майкл Витевич, профессор психологии Канзасского университета и исследователь Института продолжительности жизни Куамского университета. «Они рассказывают нам, как устроена языковая система — например, что значение хранится в памяти отдельно от звучания слов — и показывают, что воспоминания могут быть преходящими — вы использовали слово на прошлой неделе, вы не можете восстановить слово прямо сейчас, через несколько часов слово приходит к вам. Пожилые люди часто жалуются, что они чаще испытывают эти состояния, поэтому изучение состояний кончика языка помогает нам отличить то, что происходит при нормальном старении, от того, что происходит при определенных заболеваниях, таких как болезнь Альцгеймера».
Но невнятные состояния и другие речевые ошибки мешают исследователям документировать и анализировать — их нелегко воспроизвести в лабораторных условиях.
Теперь Витевич и его коллеги с факультета психологии и программисты из KU Information Technology создали веб-инструмент, позволяющий обычным людям заниматься «гражданской наукой», записывая речевые ошибки. При этом они надеются собрать самую полную базу данных речевых ошибок из когда-либо созданных и получить новое представление о приобретении, воспроизведении и восприятии языка.
Широкая общественность может получить доступ к инструменту на http://spedi.ku.edu. Исследователи надеются, что пользователи будут вводить свой собственный и чужой опыт состояний кончика языка, а также оговорок, оговорок (когда люди неправильно воспринимают слова) и мальапропизмов. Описание веб-сайта недавно было опубликовано в открытом доступе в журнале Frontiers in Psychology . «Предварительная» копия уже размещена в сети
«Вы можете думать о речевых ошибках как о случаях, когда речевая система временно «ломается», — сказал Витевич. «Как и большинство вещей, речевая система ломается в своих самых слабых местах, поэтому, собирая множество речевых ошибок и ища повторяющиеся закономерности, мы можем лучше найти слабые места в системе и определить, как она устроена. Например, когда вы меняете звуки в соседних словах, вы поменяете местами первый звук одного слова с первым звуком другого слова, но не первый звук одного слова с последним звуком другого слова. Этот паттерн предполагает, что у речевой системы есть план, который отслеживает порядок звуков в текущих и предстоящих словах».
«Как и большинство вещей, речевая система ломается в своих самых слабых местах, поэтому, собирая множество речевых ошибок и ища повторяющиеся закономерности, мы можем лучше найти слабые места в системе и определить, как она устроена. Например, когда вы меняете звуки в соседних словах, вы поменяете местами первый звук одного слова с первым звуком другого слова, но не первый звук одного слова с последним звуком другого слова. Этот паттерн предполагает, что у речевой системы есть план, который отслеживает порядок звуков в текущих и предстоящих словах».
Витевич сказал, что многие неправильные слова — или использование неправильных слов вместо похожих — вошли в популярную культуру.
«Термин «малапропизм» происходит от миссис Малапроп, персонажа пьесы Шеридана «Соперники», которая непреднамеренно использовала неправильное слово в предложении», — сказал он. «Часто слова звучат похоже, но значения очень разные. Эти ошибки встречаются в реальной жизни, но их часто используют для создания комического эффекта в пьесах и телешоу. Современный пример из реальной жизни — от бывшего мэра Чикаго Ричарда Дейли, который сказал «Единодушные Алкоголики» вместо «Анонимные Алкоголики»».0003
Современный пример из реальной жизни — от бывшего мэра Чикаго Ричарда Дейли, который сказал «Единодушные Алкоголики» вместо «Анонимные Алкоголики»».0003
Еще одна языковая ошибка, представляющая интерес для Витевича и его соисследователей, — это оговорки, также известные как «мондеградны».
«Mondegreens относятся к вещам, которые правильно говорят, но неправильно слышат», — сказал он. «Термин был придуман Сильвией Райт, которая написала, что она услышала часть песни «…и положила его на траву…» как «…и леди Мондеградн…». которые довольно забавны».
Широкая общественность также поощряется присылать «Spoonersims», ошибки, в которых перепутаны звуки соседних слов. Этот термин относится к преподобному Уильяму Арчибальду Спунеру, профессору Оксфорда, известному своими ошибками — часто с комическим эффектом, например, «вы прошипели все мои мистические лекции» вместо «вы пропустили все мои лекции по истории».
Витевич сказал, что у него появился интерес к речевым ошибкам после того, как он столкнулся с ними.
«Как и все остальные, я смеялся, когда делал или слышал, как кто-то делает речевую ошибку», — сказал он. «Я бы также испытал состояние кончика языка, как и все остальные. После первоначального смеха — или чувства раздражения в случае состояний кончика языка — я задавался вопросом, почему эти слова были проблематичными, а не другие слова, которые мне удалось произнести правильно».
Хотя Витевич нашел речевые ошибки интересным примером из реальной жизни предмета, который он изучал в лаборатории, отсутствие коллекций речевых ошибок затрудняло их использование для исследований.
«Будучи аспирантом, я попросил одного из гигантов психолингвистики прислать мне имеющуюся у нее коллекцию речевых ошибок, чтобы я мог ее проанализировать, — сказал он. «Она ответила, что каждая ошибка была записана на каталожной карточке 3 на 5 и что карточки хранились в нескольких коробках из-под обуви. Ей пришлось бы заставить своего помощника по административным вопросам стоять перед ксероксом в течение нескольких дней, чтобы просмотреть их все».
Витевич надеется, что новый веб-сайт решит проблемы с хранением ошибок и упростит их использование другими исследователями.
«Мы думаем, что данные будут полезны лингвистам, психологам, изучающим язык, логопедам, аудиологам, компьютерщикам и инженерам, работающим над распознаванием речи в компьютерах», — сказал он. «Мы также надеемся, что преподаватели на уровне K-12, а также инструкторы на уровне колледжей и университетов будут использовать данные в классных упражнениях или строить на их основе домашние задания. Наконец, делая веб-сайт доступным для всех, кто может использовать его и вносить в него свой вклад, мы надеемся привлечь больше людей, заинтересованных в занятиях наукой и задающих вопросы о том, как все устроено».
Соавторами Витевича на факультете психологии являются Cynthia S.Q. Сью, Николь Кастро и Резерфорд Гольдштейн, а также Джереми Гарст, Джон Кумар и Эрика Боос из KU Information Technology.
Этот проект был поддержан Фондом общих исследований бихевиористских наук из KU.
Канзасский университет является крупным комплексным исследовательским и учебным университетом. Миссия университета
заключается в том, чтобы поднимать студентов и общество, обучая лидеров, создавая здоровые сообщества и делая открытия
которые меняют мир. Служба новостей КУ является центральным отделом по связям с общественностью кампуса Лоуренса.
[email protected] | 1450 Jayhawk Blvd., Suite 37, Lawrence, KS 66045
речевых ошибок
Речевые ошибки,
Модели производства речи и патология речи
Авторское право
Обратите внимание: Этот материал был написан
и опубликовано в Уэльсе Дереком Дж. Смитом (дипломированным инженером). Он является частью
многофайловый ресурс электронного обучения и подлежит только признанию Дерека Дж.
Права Смита в соответствии с международным законодательством об авторском праве быть идентифицированным как автор могут
свободно скачиваться и распечатываться в единичных полных экземплярах исключительно для
в целях частного изучения и/или обзора. Права на коммерческую эксплуатацию
Права на коммерческую эксплуатацию
сдержанный. Удаленные гиперссылки были выбраны для академического соответствия
их содержания; они были свободны от оскорбительного и спорного содержания, когда
выбран, и будет периодически проверяться, чтобы он оставался таковым. Авторское право
2003-2018, Дерек Дж. Смит .
Впервые опубликовано в 08:00 по Гринвичу 29 октября 2003 г .; эта версия
[2.0 — авторские права] 11:00 BST 9 июля 2018 г.
Некоторые из этих
материал появился у Смита (1997).
Здесь он был значительно расширен и дополнен гиперссылками. Речь
и студенты языковой терапии, вероятно, выиграют от обновления своих
воспоминания о разнице между сегментарным и надсегментарным
фонология [глоссарий]
прежде чем продолжить.
1 — Повседневная речь
Ошибки
Когда язык
производственная система работает правильно, ее легко недооценить.
сложность. Однако время от времени система дает сбои и выдает ошибку.
ошибки, а ошибки в любой системе могут иметь огромное объяснительное значение. Они
может сказать нам, например, выходят ли отдельные функции из строя по отдельности
или вместе, и, следовательно, являются ли они, вероятно, производными от одного или нескольких модульных
процессы. При дальнейшем анализе они также могут сказать нам, какие модули
общаться с какими другими модулями, какая форма кодирования передается
назад и вперед, и насколько хорошо защищены каналы связи от
повреждение или вмешательство. В этом разделе мы рассмотрим наиболее распространенные типы
повседневная речевая ошибка.
1.1 Бланки
Язык
В раннем изучении ошибок, которые мы все
сделать в нашей повседневной речи, Бумер и Лейвер (1968) пришли к выводу, что фраза была
одна из основных единиц речевого производства. Они основывали это суждение на
эмпирическое наблюдение, что ошибки редко выходят за границы фразы. Бумер
и исследование Лейвера вызвало волну интереса к этой тематической области, и
кульминацией в некоторых мощных новых теорий. Использовались данные корпуса ошибок, для
Использовались данные корпуса ошибок, для
например, Гэри С. Делл из Института Бекмана, Университет Иллинойса,
развить его «Распространение теории активации» лексического доступа
[будет подробно обсуждаться в разделе 3.1]. Делл (1986) выделяет три уровня
ошибки оговорки, следующим образом …..
(a) Звуковые ошибки: Это
случайные замены звуков между словами. Таким образом, «снежные бури»
может стать «потоком». (Бумер и
Лейвер уже утверждал, что 90 283 сегментарных 90 284 ошибок, таких как эта учетная запись
около 60% всех ошибок.)
(b) Морфемные ошибки: Это
случайные замены морфем между словами. Таким образом, «самоуничтожение
инструкция» может стать «самообучение уничтожению».
(c) Word Errors: Это
случайные перестановки слов. Таким образом, «Написание письма моему
мать» может стать «Пишу маме письмо».
Кроме того, каждый из этих трех уровней ошибки
может принимать различные формы …..
(a) Ожидания: Где рано
выходной элемент поврежден элементом, принадлежащим более позднему. Таким образом, «список чтения» — «лидирующий список».
Таким образом, «список чтения» — «лидирующий список».
(б) Персеверации: Где позже
выходной элемент поврежден элементом, принадлежащим более раннему. Таким образом
«бодрствующие кролики» — «бодрствующие ваббиты».
(c) Удаление: Где вывод
элемент как-то полностью потерян. Таким образом, «такое же состояние» — «такое же состояние».
Dell затем указывает, что существует четкая той же категории
шаблон для большинства ошибок. Таким образом, начальные согласные будут взаимодействовать
преимущественно с другими начальными согласными, префиксами с другими префиксами и
существительные с существительными. Это согласуется с вербальным хранением и поиском
процессы также организуются на основе какой-то одной категории. Делл также
указывает на феномен «аккомодации» , на то, что
ошибка на ранней стадии вывода может, тем не менее, благополучно продолжаться через
все остальные выходные каскады, без обнаружения, и с последующим
синтаксические и морфологические изменения применяются правильно, но неуместно.
Упражнение 1 — 1 Блокировать копирование немедленно Ожидание, персеверация, транспозиция и удаление 2 Прочитайте получившийся текст вслух. |
Стефани Шаттак-Хафнагель из Массачусетского технологического института
сосредоточился на роли согласных в начале слова в планировании производства речи.
(Шаттак-Хуфнагель, 1987). Она нашла то, что она
позвонил «подлексические» ошибки — речь
ошибки в доставке в противном случае правильно выбранного реального слова — склонны
в основном для воздействия на согласные в начале слова. Она объяснила это, используя «слот-и-заполнитель» .
модель построения слова, в которой предлагается отдельная
представление (а) сегментов (или «наполнителей») и (б) каркаса
(или «кадр») из «слотов» , чтобы зафиксировать эти сегменты в
должность. Полная модель работает следующим образом …..
«Шаг 1. Выбор набора кандидатов открытого класса или
содержание слова из лексикона [глоссарий
— обратите внимание, что есть два существенно разных употребления этого слова, и что
Шаттак-Хюфнагель здесь, по-видимому, использует
психолингвистический — Ред.]. Отбор может быть осуществлен путем
передача лексических единиц в хранилище краткосрочной обработки или путем маркировки
их лексические представления временно [см. NB ниже]. Эти кандидаты
лексические единицы представляют набор фонематических сегментов, среди которых окончательный выбор
ибо произношение будет сделано, и среди которых могут возникать ошибки взаимодействия .
Форма каждой лексической единицы определяет ее сегменты и их порядковые номера.
заказ. Шаг 2. Построение
слоговая структура и другой аппарат для связывания основного лексического ударения с
лексические единицы открытого класса.
Эти процессы включают в себя остальную часть слова без начала; начало слова
согласные игнорируются до последнего. Шаг 3. Передача
или ассоциация неначавших частей содержательных морфем, теперь организованных
в метрические структуры, управляющие лексическим ударением, в возникающие
фразовый каркас. В то время как иерархическая структура фразовых фреймов,
получать неначалные части слов содержания не полностью указано в
этой модели мы предлагаем, среди прочего, определить два класса
компоненты для заданий открытого класса: места начала слов (которые на данный момент в
обработка остается пустой) и места для остальной части каждого слова (которое
уже заполнены). Эти два структурных компонента присутствуют в каждом
содержательное слово во фразовом каркасе, даже для слов с начальными гласными, чьи
согласный компонент в начале слова не будет заполнен.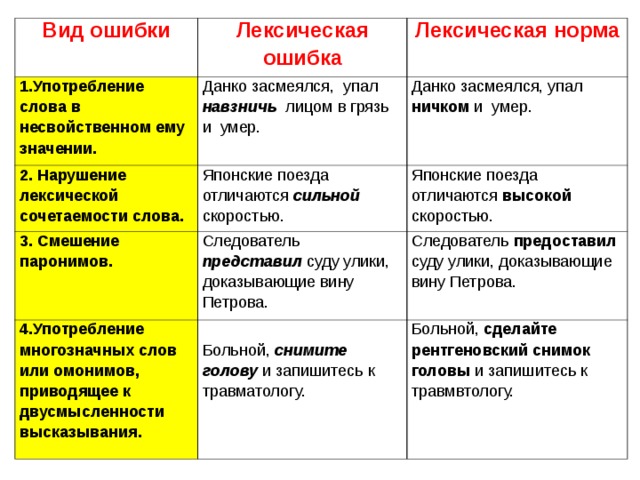 Шаг 4.
Шаг 4.
Возможная передача или ассоциация согласных в начале слова
в места начала слов для содержательных слов во фразовом фрейме.
Все сегменты содержательных слов фразы теперь на месте. Шаг 5. Преобразование этого представления с его
сопровождающую иерархическую организацию в полную цепочку дискретных полностью
определенные сегментные элементы, в том числе грамматические морфемы, и
впоследствии в паттерн моторных команд, характеризующийся значительным
временное перекрытие эффектов соседних сегментов. Этот процесс предположительно
включает в себя много шагов, среди них один, который подвержен односегментным ошибкам на
любая позиция в слове. Влияние надсегментарных
структура ошибок взаимодействия на данном этапе обработки не ясна,
но ошибки невзаимодействия, которые более равномерно распределяются по слову
позиции, могут встречаться здесь» (Shattuck-Hufnagel,
1987, стр. 47; добавлен жирный шрифт)
1.2 Спунеризмы
Интересным подтипом звуковых ошибок является
«спунеризм». Спунеризм часто представляет собой забавную группу
Спунеризм часто представляет собой забавную группу
ошибки транспонирования начала слова и названы в честь оксфордского академика,
Преподобный У. А. Спунер (1844-1930), у которого скорбь — безопасно
поверьте — произошло само собой (по крайней мере, для начала). вот несколько примеров
собственных измов Спунера …..
- He
сделал выговор ученице за «Борьба с лжецом в четверке» . - А
другой за «прошипел свою таинственную лекцию» и за то, что
поэтому «отведал двух червей» . - И он
произнесла тост за Ее Высочество Викторию: «Три ура нашему странному
декан!»
Два качества отличают спунеризм от
обычные звуковые ошибки. Во-первых, транспозиция звука порождает два
собственные слова, а второе состоит в том, что два новых слова сами по себе создают некоторые
разный смысл вместе. Однако внимательное изучение естественной истории
явление поднимает другие интересные наблюдения. Вот ранний скептик, который
Вот ранний скептик, который
явно считал, что Спунер выжимает из своего дефекта все возможное…..
«Любопытно
Достаточно того, что спунеризм назван в честь человека, который редко делал спунеризм как
словари определяют их. Недавнее исследование [Роббинс (1966)] показывает, что
Spooner’s Spoonerisms были довольно тщательно спланированы — юмор высокого уровня скорее
чем непреднамеренная ошибка …..» (Mackay, 1970, стр. 323)
Маккей проанализировал ранее опубликованные списки
Спунеризм, тщательно отвергающий все, что может быть расценено как преднамеренное
юмористические или иным образом ложные. Подробный анализ 179примеры, которые
Оставшиеся привели его к ряду выводов относительно вероятных единиц
речевое производство. Вот конкретные наблюдения Маккея
…..
«1.
Повторяющиеся фонемы обычно встречаются до и после обращенных фонем. 2.
Инверсии перед повторяющимися фонемами были столь же распространены, как и инверсии после повторения.
фонемы, противоречащие теориям цепных ассоциаций. 3. Слоговая позиция
3. Слоговая позиция
перевернутые фонемы почти всегда были идентичными, что указывало на то, что слоги должны быть единицей
в речевом производстве. 4. Согласные в начальной позиции слогов были
чаще переворачивается, чем можно было бы ожидать случайно […..] 5.
Значительно больше инверсий было связано с исходной фонемой слов, чем могло бы быть.
ожидаться случайно, что указывает на лексический фактор в Spoonerisms. 6.
Отличительные признаки обращенных фонем обычно были сходны, за исключением места.
артикуляции […]. Это предполагало возможность существования двух различных типов
механизма речеобразования: один для формы артикуляции, в том числе
голос, гнусавость и открытость, и еще один для места артикуляции. 7.
Согласные транспонировались чаще, чем гласные. 8. Перевернутые фонемы
встречались ближе друг к другу в словах и предложениях, чем можно было ожидать
шанс. 9. […..] Спунеризмы в немецком и английском языках оказались
количественно похожи [как были] Spoonerisms на латыни, хорватском, греческом и
Французский, предполагая, что инверсия фонем может быть результатом универсальной основы
механизмы, общие для всех ораторов. 10. Не найдена опора для цепи
10. Не найдена опора для цепи
ассоциативных объяснений спунеризмов…» (Mackay, 1970, стр. 347)
Затем Маккей предположил существование некоторого рода
«буферная система» , то есть временное хранилище памяти
расположен на полпути вниз по моторной иерархии [напомните мне об этом]
и работает по принципу «хранение-и-вперед».
ОТДЕЛЬНО: Это использование термина
«буфер» возник в компьютерных науках, где он позволяет отправлять
модуль и приемный модуль для работы на несколько разных скоростях, если
необходимый. Выход из отправляющего модуля передается в буферное хранилище в
скорость, которую отправляющий модуль находит удобной, и чтение из буферного хранилища с помощью
приемный модуль со скоростью, которую приемный модуль считает удобной. С
незначительные задержки обработки теперь могут компенсироваться отдельными модулями,
работа системы в целом может при небольших вложениях в
промежуточный ресурс, быть значительно улучшены.
Вот как Маккей видел работу системы ментального буфера . ….
….
«В
в настоящем исследовании перевернутые фонемы всегда возникали в одной и той же фразе,
что далее говорит о том, что буферная система отображает не более одной фразы
вовремя. Слог должен быть другой единицей, поскольку перевернутые фонемы имеют тенденцию
сохранять ту же слоговую позицию. Однако […] тот факт, что в
Spoonerisms единица меньше, чем слог пересекает границы слога,
предполагает существование более мелких единиц. Теперь возникает вопрос о том,
фонемы являются единицей в этой иерархии. […..] Другой блок вопросов касается
к буферной системе. Сколько указано в буферной системе? в
В настоящей модели, например, продолжительность фонем не указана, но
отмечены фонемы, слоги и ударение. В какой форме представлены единицы
буфер указан? Представлены ли в буфере артикуляционные цели или задачи?
а не фонемы? Является ли стресс независимым от элементов, которые подвергаются стрессу?
Как кодируются слоги — в абстрактной форме, независимой от фонетических элементов
включая их?» (Маккей, 1970, pp341-346)
Этот вид прогрессивного кодирования и перекодирования,
конечно, это классический материал для пояснительной диаграммы со стрелкой, и,
конечно, Mackay обязывает . ….
….
Рисунок 1 — «Когда Если эта диаграмма . http://www.smithsrisca.co.uk/PICmackay1970.gif |
Перерисовано с |
 348)
348) 1.3
Феномен «Кончик языка»
Это имя, данное относительно
повседневный опыт, когда мы более или менее знаем слово, которое хотим сказать следующим,
но не в состоянии довести это до сознания. Явление имеет
известно в течение некоторого времени, но недавний интерес обычно приурочен к Брауну
и McNeill (1966), которые провели психолингвистическое исследование 56 американских
студенты. Они выбрали 49 низкочастотных слов (таких как апсида , непотизм ,
клоака , амбра и сампан ) и подготовлен краткий словарь
определения каждого. Испытуемым давали лист ответов (аналогичный тому, который использовался
Испытуемым давали лист ответов (аналогичный тому, который использовался
в упражнении 2 ниже), а затем были представлены каждое определение (так же, как
открывая словарь наугад, читая запись, а затем пытаясь угадать
слово, к которому оно относится). Когда испытуемые либо знали, либо не знали цель
Словом, ответа не требовалось, но примерно в 8,5% испытаний они
испытал на кончике языка (ТОТ) состояние — их словарный запас почти
доставил им целевое слово, но не совсем. В этих случаях они были
требуется угадать первое или последнее пропущенное слово
буквы, количество слогов, которые в нем содержались, и какой слог они считали
несли основное напряжение. Однако, прежде чем мы обсудим их результаты, вот
возможность испытать это явление на себе
…..
Упражнение 2 — Совет
языкового феномена
Подопытные Брауна и Макнейла испытали в общей сложности
из 360 ТОТов, из них 233 «положительных ТОТов» , т.е.
сказать, ТОТ, «для которых полученные данные могут быть оценены как точные или
неточные» (стр. 280), а остальные — «отрицательные ТОТ» ,
280), а остальные — «отрицательные ТОТ» ,
то есть ТОЦ, по которым испытуемый судил о прочитанном слове не
была его мишенью и, кроме того, той, в которой субъект оказался
не может вспомнить свою функциональную цель» (стр. 281).
оценивали, были ли ТОТ похожи по звучанию ( Сайпан , возможно, за Сампан )
или смысл ( плавучий дом , возможно, для сампан ) к цели. Там
были 224 похожих по звучанию (SS) TOT и 95 похожих по смыслу (SM) TOT. СС
предметов, 48% имели то же количество слогов, что и цель, по сравнению только с 20%
слов СМ. Затем эти данные были смоделированы так, как если бы человеческое слово хранило
были организованы как словарь, хотя и очень сложный
…..
«В
настоящих словарей, тех, что являются книгами, статьи упорядочены по алфавиту и
связаны на месте. Такое устройство слишком просто и слишком негибко, чтобы служить
как образец ментального словаря. Предположим, что слова вводятся на карточках сортировки ключей, а не на страницах, и что карточки
пробиты для различных особенностей введенных слов. С настоящими картами, бумажными, из общей колоды можно извлечь любую
С настоящими картами, бумажными, из общей колоды можно извлечь любую
подмножество пробито по общему признаку, вставив металлический стержень через соответствующий
отверстие. Мы предположим, что в уме существует некий более быстрый эквивалент
эта техника поиска. Модель будет описана в терминах одного
пример. Когда целевое слово было секстант , испытуемые услышали
определение: «Навигационный прибор, используемый для измерения угловых расстояний,
особенно высота солнца, луны и начало в море». Это определение
вызвало состояние ТОТ у 9 испытуемых из 56. […..] Проблема
начинается с определения, а не со слова, и поэтому субъект должен войти в свою
словарь задом наперед или таким образом, который […] был бы совершенно невозможен для
словарь, который является книгой. Это не невозможно с помощью сортировки ключей
карты, при условии, что мы предполагаем, что карты перфорированы для некоторого набора семантических
Особенности. [….. Однако] в случае ТОТ [поиск] должен включать карту
с определением секстант введен на нем но с самим словом
введен не полностью» (Brown and McNeill, 1966, стр. 292–293; курсив
292–293; курсив
оригинал)
Браун и Макнейл затем подробно обсуждают именно
как эта неполная лексическая запись может быть закодирована. Самое очевидное предложение
было то, что он был закодирован первой и последней буквами, так что кастрюля , космонавт ,
и тычинки будут каким-то образом сгруппированы вместе — отсюда Сайпан-сампан
путаница. Но это было отвергнуто как слишком упрощенное. Вместо этого они
предпочел «что-то вроде Sex_tanT »
(стр. 295), где не только первая и последняя буквы, но и элементы
также играли роль первый и последний слоги. Браун и Макнейл назвали этот тип
отзыва по общему признаку «общий отзыв» , и увидел его как
отражающие системы кодирования, используемые в словесной памяти. Это делает ТОТ
само явление, а также приемы экспериментирования с ним, соответствующие
в широком спектре коммуникативного познания, включая восприятие речи,
составление предложений и чтение, как теперь продемонстрировано . ….
….
Упражнение 3 —
Доступ к лексикону по первой и последней буквам
Только
Совсем недавно Джонс и Лэнгфорд (1987) и Мэйлор (1990) рассмотрели, как различные типы
отвлекающее слово может помешать феномену ТОТ. Мэйлор,
например, представили предметы ТОТ 15 испытуемым в возрасте 50 лет, 17 в возрасте
шестидесятых и семнадцати восьмидесятых. Было представлено отвлекающее слово
сразу после каждого определения цели, разделенные только коротким звуковым сигналом.
Эти отвлекающие факторы были тщательно отобраны, чтобы попасть в одну из четырех категорий.
условия. В состоянии P дистрактор был фонологически связан с
целевое слово (например, балка для тушение ), в
Условие S было семантически связано (например, инкуб
для banshee ), в условии U это никак не связано (например, окаменелость для хоспис ), а в условии
PS это было одновременно фонологически и семантически родственно (например, аномалия для анахронизм ). Они
Они
различать субъективных ТОТ , где субъект сообщил о состоянии ТОТ, но
не смог найти никаких конкретных фактов об этом, и объектив ТОТ , где
можно было идентифицировать букву или буквы, а также количество слогов или место ударения
данный. Их результаты показали, что оба состояния возникают чаще, когда
слово-дистрактор было фонологически связано с целевым словом, чем когда оно было
фонологически не связаны.
А совсем недавно Harley and Bown (1998) варьировали частотные и фонологические
различимость целевых слов и обнаружили, «что TOTs более вероятны
возникать на низкочастотных словах, у которых мало близких фонологических
соседей» (стр. 151). Они используют свои данные, чтобы размышлять о более широком
процесс «лексикализация» , которую они определяют как »
процесс фонологического поиска в речеобразовании с учетом семантического
ввода» (стр. 152), и они выбирают «двухэтапный» пояснительный
модель лексического доступа, то есть модель, строго разделяющая каждый
семантическая и фонологическая репрезентация слова. Таким образом, TOT можно рассматривать как
Таким образом, TOT можно рассматривать как
возникающие, «когда первый этап лексического доступа завершен успешно,
но не второй» (стр. 152-153). Однако критическая точка, насколько
Харли и Боун обеспокоены следующим …..
«Наш
центральным результатом является то, что фонологические соседи способствуют, а не
препятствовать фонологическому поиску в речевом производстве. […..] TOT происходит, когда
семантическая спецификация успешно обращается к абстрактной лемме. Это вызывает «чувство знания» слова. Тем не менее,
тогда лемма не может передать достаточную активацию и тем самым получить доступ
соответствующую фонологическую форму слова. […..] Возможны две причины
за провал на этом этапе. Либо связи между леммой и
фонологические формы могут быть ослаблены, или фонологические формы могут
сами слабо представлены по этим предметам» (Harley and Bown, 1998, p162)
Наконец, хотя этот раздел в основном
связанные с речевыми ошибками в норме,
сходство между феноменом ТОТ и клиническим признаком, известным как
«аномия» слишком бросается в глаза, чтобы не получить комментарий. Гудглас,
Гудглас,
Каплан, Вайнтрауб и Акерман (1976) изучали конфронтационное именование.
способности популяции афазиков, и начал с указания на это самое сходство…..
обозначение пациента как «аномичного» указывает на то, что его доступ к лексическим терминам
плох в отношении беглости его артикуляции и грамматики» (Гудгласс и др., стр. 145).
Гудгласс и др. затем
смотрели на «молчаливое знание» пациентами первой буквы и
количество слогов, слова, которые они не смогли найти. Фактически,
они датировали такого рода исследования Вейзенбургом и
Макбрайд (1935), который официально зафиксировал, сколько слогов в аномике.
мысли заключались в потерянных именах (тест, известный как тест Пруста-Лихтхайма).
Тест внутренней речи, в котором пациенты показывают, поднимая соответствующий
количество пальцев, сколько слогов, по их мнению, в слове, которым они являются
возникли проблемы с). В своем собственном исследовании Goodglass
и соавторы протестировали 42 мужчин с афазией, классифицированных Бостонским диагностическим тестом на афазию.
13 типов Брока, 8 типов Вернике, 12 проводниковых типов и 9аномический тип. Каждому было показано 48 штриховых рисунков.
карточки-стимулы предметов, название которых имело промежуточную частотность слова в
английский и содержащий один, два, три или четыре или пять слогов [для
например, хомут , морж, скрипка и холодильник ). Авторы делают вывод …..
»
результаты показали явное превосходство со стороны
проводниковой афазии по сравнению с Вернике и аномическими субъектами.
Проводниковая афазия идентифицировала как первую букву, так и длину слога одного
треть слов, которые они не могли назвать. Аномическая афазия преуспела менее чем в одном из десяти случаев, а афазия Вернике была
не намного успешнее. Афазия Брока была
правильный в одной попытке из пяти, и не может быть дифференцирован статистически
либо от проводниковой афазии, с одной стороны, либо от афазии Вернике
с другой» (Гудгласс и др., 1976, p151)
Что касается того, почему это должно быть, авторы рассмотрели
последовательный характер процесса производства слов. ….
….
«…..
кажется, что поиск слов обычно
метод «все или ничего» для Вернике и пациентов с аномией в том смысле, что они
либо восстановить имя достаточно хорошо, чтобы произвести его, либо они могут дать мало
свидетельствует о частичном знании. Слова, которые не удались, кажутся полностью
недоступен, что касается процессов отзыва. Однако почти идеальный
множественный выбор всеми субъектами указывает на то, что это односторонний
расстройство, связанное с воспоминанием, но не узнаванием, [//] В случае
при афазии проводимости признаки молчаливого частичного знания многих слов могут
указывают на разбивку на более позднем этапе процесса наименования. Внутренний слух
представительство может присутствовать, но не может привести в движение
заключительные нейронные события, которые активируют артикуляционную систему. Либо слуховой
модель неполна или, как предполагает гипотеза об отключении, ее путь к
моторная речевая область не постоянно доступна. [//] Несоответствие афазии Брока выполнению проводимости
афазия удивительна, так как противоречит традиционному представлению
что их трудности с подбором слов связаны исключительно с моторной речью
уровне» (Гудгласс и др. , 1976, стр. 152)
, 1976, стр. 152)
Другие различия между проводимостью и
транскортикальные моторные типы афазии обсуждаются у McCarthy и
Уоррингтон (1984).
1,4
Малапропизмы
Малапропизмы — еще одно явление, при котором
эмпирические данные бросают вызов предпочтительной модели лексической организации, таким образом …..
«От
сборник из более чем 2000 речевых ошибок, составленный первым автором, мы
изначально отобрали все ошибки, связанные с заменой слов (397). Из этого
исходный список, мы устранили все ошибки, которые могли возникнуть из-за [других
источники]. Оставшийся корпус содержал 183 ошибки. Эти ошибки, т.
малапропизмы, обладают некоторыми интересными свойствами. Во-первых, цель и ошибка
относятся к одной грамматической категории в 99% случаев. Во-вторых, цель
и ошибка часто имеют одинаковое количество слогов (87% совпадений в
наш список). В-третьих, у них почти всегда одинаковая картина стресса (98%
соглашение)» (Фэй и Катлер, 19 лет).77, стр. 507-508).
507-508).
Фэй и Катлер продолжают…..
«В
определенный момент в построении предложения должна быть грамматическая конструкция
обрамлено, чтобы нести смысл, который говорящий намеревается передать. Эта структура
можно рассматривать как включающее в себя как синтаксические свойства
предстоящее высказывание (в виде, скажем, фразовой структуры), а значения
слов, которые будут использоваться. То, чего нет в структуре изначально, есть любое
уточнение фонологических характеристик выбранных слов. Для
устройство воспроизведения речи должно заглянуть в свой мысленный словарь, чтобы найти
конкретная запись, значение и синтаксическая категория которой соответствуют специфике
воплощены в грамматической структуре. […..] Что это за мысленный словарь,
или лексикон, как? Мы можем представить его как нечто подобное печатному словарю,
то есть как состоящий из пар значений со звуковыми представлениями. А
в печатном словаре у каждой статьи есть произношение слова и его
определение через другие слова. Точно так же ментальный лексикон
Точно так же ментальный лексикон
должны представлять по крайней мере некоторые аспекты значения слова, хотя
конечно, не так, как печатный словарь; так же должно
включать информацию о произношении слова, хотя, опять же,
вероятно, не в той же форме, что и обычный словарь» (Фэй и Катлер,
1977, стр. 508-509; добавлен жирный акцент; обратите внимание, что эти авторы используют
лингвистическое определение лексики, а не психолингвистическое — см.
глоссарий)
2 — Сомнения
как индикаторы времени обдумывания
«Время
есть мера всех вещей, не в последнюю очередь умственной деятельности; и время, когда
люди, кажется, ничего не делают, это то время, которое психологи больше всего любят
измерять» (Баттерворт, 1980, стр. 155)
Идея о том, что явление колебания может указывать
время психологической обработки восходит к Дондерсу.
работы 1860-х годов, но современный интерес лучше всего связан с работами Фриды
Гольдман-Эйслер (разные от 1951). В одном из нее
ранние исследования (Голдман-Эйслер, 1958), она
показали, что паузы колебания предшествовали фразам, богатым новой информацией.
Затем за ней последовал Дональд С. Бумер, изучавший отношения между
как заполненные, так и немые паузы и их положение в грамматическом предложении
(например, Бумер, 1965). Бумер
лента записала спонтанную речь 16 американских студентов мужского пола и проанализировала
стенограммы пауз продолжительностью более 200 миллисекунд, заполненных пауз и
границы надсегментного «фонематического предложения» …..
Ключевое понятие — фонематическая оговорка: «Фонематическая оговорка — это интонационная единица, состоящая из одной интонации.
контур, одно первичное напряжение и конечное соединение, а также называется «тоновым
группа» (Butterworth, 1980, стр. 156–157).
грамматическая структура, созданная в пределах одного интонационного контура и ограниченная
соединениями [молчанием или значительными изменениями в фонетической высоте, ударением или
продолжительность].» (Кристалл, 2003, стр. 348)
Бумер затем пронумеровал следующее слово
границы в предложениях, исходя из того, что они представляют собой «упорядоченный
ряд возможностей для колебаний» (стр. 162). Например,
162). Например,
…..
1 and 2 the 3 weather 4 was 5 hot
Here is his argument …..
«В
в общем, возможных мест будет столько, сколько слов в предложении, каждое
местоположение помечается порядковым номером слова, которому оно предшествует.
Иногда в этом исследовании были сделаны произвольные исключения для многоэлементных
имена собственные, такие как Билл Смит и Сан-Франциско , для
комбинаторные группы, такие как спасибо и как вы можете называть это , и
для определенных «тегов», таких как , вы знаете и , вы видите . Это были
считались отдельными словами, как и синтаксически лишние повторения
слов, как в я сел на … поезд . Сами заполнили паузы и
фрагменты слов также исключались из подсчета. [//] Корпус содержал
всего 1593 фонематических предложения, из которых 713 содержали одно или несколько колебаний.
Колебания составили 1127, 749 незаполненных пауз и 378 заполненных пауз. […..] Полученные результаты. Гипотеза о том, что колебания имеют тенденцию
начало фонематических предложений было сильно поддержано [хотя]
наибольшая частота колебаний не в начале, а в позиции 2, после
первое слово предложения [см. столбец данных, выделенный красным цветом в
ниже таблица — Ред.]. Это верно для всех девяти распределений массивов.
длина предложения от двух до десяти слов» (Бумер, 19 лет).65,
стр. 162-163; курсив оригинальный; добавлен жирный шрифт)
Rochester (1973) предоставляет удобный обзор
ранняя литература по колебаниям, если интересно.
2.1 Работа Линдсли
Линдсли (1975)
разработали исследование, чтобы определить, сколько единиц предложений планируется заранее
начало речи. Отметив, что подлежащее и основной глагол вводят часть
предложение, известное как сказуемое, он выделил три возможных планирования
стратегии, следующим образом…..
Модель до предиката: Это
Модель «характеризует говорящего, который инициирует свое высказывание, как только он
завершил выбор предмета» (Линдсли,
1975, стр. 3).
3).
Пост-предикатная модель: Это
Модель «характеризует говорящего, который откладывает начало своего высказывания до тех пор, пока
после того, как он выберет как глагол, так и подлежащее» (Lindsley, 1975, p3).
Модель полусказуемого: Это
компромиссная модель, которая «характеризует говорящего, который откладывает начало
свое высказывание до тех пор, пока он также не завершит некоторый выбор глагола
как выбор предмета» (Линдсли, 1975,
pp3-4)
Теперь о трех объяснительных моделях
заключается в том, что они делают разные прогнозы по задержке инициации.
предикатная модель предсказывает, что подлежащий выбору глагол ничего не вносит
к любой задержке начала речи и, как следствие, что «говорящий
отвечает так, как будто рассматривает подлежащее и глагол как независимые
ответы» (p3). Пост-предикатная модель предсказывает, что выбор глагола
способствует латентности инициации и, как следствие,
говорящий отвечает так, как если бы он рассматривал подлежащее и глагол как взаимозависимые
аспекты более крупной единицы ответа: предложения в целом» (стр. 3).
3).
полупредикатная модель находится между этими двумя крайностями, принимая некоторые
вклад в латентность от выбора глагола.
Чтобы проверить, какая модель может работать, Линдсли разработал задачу описания изображения для создания
данные о задержке ответа. Он показывал испытуемым картинки с изображением актера.
(мужчина, женщина, девочка или мальчик), занятые определенным действием (касание, пинок,
приветствие и т. д.), и сравнивали задержки ответа при произнесении
различной длины и грамматической формы …..
S-только предложения: Здесь
испытуемый должен был назвать актера, изображенного на карточке. Пример : »
девушка».
V-только предложения: Вот
испытуемый должен был назвать действие, изображенное на карточке. Пример :
«Приветствие».
S-V Предложений: Здесь
субъект должен был назвать и актера, и действие в форме предложения. Пример :
«Девушка здоровается».
S-V-O Предложения: Здесь
субъект должен был назвать актера, действие и объект в форме предложения. Пример :
Пример :
«Девушка приветствует мальчика».
Объем принятия лексических решений также был
варьироваться, удерживая S или V постоянными на нескольких картах, так что (a)
это всегда будет, скажем, девушка, которая что-то делает (S константа), или (b)
действие всегда будет приветствием, скажем, независимо от того, какой актер был
изображено (постоянное V). Там, где были возможны другие S или V, Линдсли кодирует их как dS, dS + dV и dV.
фразы; где константа S или V, коды Линдсли
их как cS, cV и т. д. Данные
затем были получены для всех перестановок c и d и типа предложения, включая
смешанные предложения, такие как cS + dV.
Эти данные показали (а), что для инициации высказывания S-V требуется больше времени, чем
высказывание только для S, что противоречит модели до предиката, и (b) что
Реплики S+V были короче, чем только S-называние, когда актер уже был
известны, тем самым выступая против пост-предикатной модели. Линдсли
поэтому сделал вывод…..
«…..
кажется наиболее вероятным, что динамики S-V
предложения, представленные dS + dV
и cS + dV постоянно используют
специфическая речевая стратегия, характеризуемая полупредикатной моделью. Этот
Этот
Речевая стратегия предполагает, что начальная часть выбора глагола преднамеренно
выполняется до начала высказывания. Всякий раз, когда эта начальная часть
выбор глагола происходит последовательно с выбором подлежащего или занимает больше времени, чем
любые параллельные этапы отбора субъектов, это задерживает начало
высказывание до тех пор, пока оно не будет завершено. […..] Результаты этого
исследований, выделив полупредикатную модель, согласуются с таковыми
исследования колебаний [цитаты] в демонстрации того, что речь инициируется
до того, как вся информация о высказывании будет обработана или лингвистически
закодировано» (Линдсли, 19 лет).75, стр. 10-19)
Или, проще говоря, обычно мы начинаем говорить
к идее, как только мы определились с предметом и имеем некоторое представление о
действие, которое мы хотим описать.
2.2
Работа Баттерворта
Баттерворта (1975) изучала не личность
паузы — то, что он называл «микроструктурой колебаний», — но
скорее общая пропорция пауз к речи —
«Макроструктура колебаний» (Баттерворт, 1975, стр. 75). Он
75). Он
принял Хендерсона, Гольдмана-Эйслера и Скарбека (1966) понятие о «временном
циклов» 90 774 речи, то есть чередование периодов нерешительности
и беглость, а также собрали образцы речи восьми мужчин. Затем он
проанализировали транскрипты этих образцов на предмет демаркационных точек обоих
циклы и идеи. Вот его выводы…..
«Ст.
границы представляются необходимым, но недостаточным условием возникновения
как циклов, так и новых Идеи, в том, что подавляющее большинство циклов и Идеи
деления, даваемые любым предметом, совпадали с границами предложений, но очень
значительное количество границ пунктов не совпадало ни с одним из циклов
или Идеи. Было несколько лучшее соответствие между предложениями, идеями и циклами.
Принятие идей и предложений в первую очередь из 35 критериальных идей
границы — т.е. куда
более половины испытуемых сошлись во мнении о местонахождении отдела Идеи — все
но четыре совпали с границами предложения […]. Таким образом, из типов предложений
релевантным видом для идей, по-видимому, являются предложения; но Идеи могут состоять из большего
чем одно предложение. [//] Что касается циклов, то примерно половина совпала с
[//] Что касается циклов, то примерно половина совпала с
начало предложения и три четверти будут всевозможными границами предложения. это
левые циклы, состоящие более чем из одного предложения в некоторых падежах и частях
предложения примерно в половине случаев […..//] Результаты, представленные здесь,
согласуется с гипотезой о том, что циклы представляют собой интегральное планирование
единицы для говорящего, и пролить свет на то, из чего состоят эти единицы планирования
лингвистически. Во-первых, говорящий имеет тенденцию планировать заранее с точки зрения
хорошо понятные языковые единицы, а именно пункты и предложения. Во-вторых, он появляется
иметь возможность объединять несколько предложений или предложений в одно целое
вышестоящая плановая структура, объединенная неким смысловым единством.
[…..] Если это верно, то требуется серьезная квалификация
Тезис Бумера о том, что основной единицей планирования является фонематическое предложение (Бумер,
1965; Бумер и Лейвер, 1968). Если говорящие действительно кодируют речь в фонематическую
Если говорящие действительно кодируют речь в фонематическую
единицы предложения, то это произойдет далеко вниз по иерархии кодирования
процессов и будет процессом совершенно иного рода, чем планирование
циклические сегменты.» (Баттерворт, 1975, стр. 83-84)
В более поздней статье Баттерворт (1980) повторно рассмотрел
важность данных колебаний. Он начал с того, что указал на это предложение
пограничные паузы, вероятно, помогают слушателям не меньше, чем говорящим, потому что они дают
им время, чтобы закрепить свое понимание только что полученного сообщения. Он
затем снова использовал циклы, описанные Хендерсоном, Гольдманом-Эйслером и Скарбеком (1966) …..
«Обычно,
циклы длятся около 18 с, но некоторые до 30 с, что означает, что они будут
содержат в среднем от пяти до восьми предложений, т.е. обычно два или более предложений [цитаты]. Поскольку, как мы
видели, семантические факторы были ответственны за вариации времени паузы, мы
следует искать семантические, а не синтаксические единицы. [//] Поэтому и спросил
[//] Поэтому и спросил
независимым судьям разделить стенограммы выступлений типа «Идеи» […..]. Принимая
те моменты в текстах, где более половины судей сошлись во мнении, что одна Идея
закончилось и началось следующее, и сравнение их с границами цикла, значительное
найдено соответствие между Идеей и границами цикла. Хотя
переписка была достоверной она не была полной. Некоторые циклы не начинались в
граница Идеи, и некоторые Идеи не совпадали с циклами. Почему эти
несоответствия должны возникать не ясно. […..] Одно установлено,
однако: границы идеи и цикла почти всегда совпадают с пунктом
границы. » (Баттерворт, 1980, стр. 165; выделение жирным шрифтом)
системной концепции, и, действительно, указывает, что вполне может быть более чем один из
вещи, о которых нужно беспокоиться …..
«Несколько
авторы, прежде всего Мортон (1970), выступали за «буфер отклика», который
может содержать строку слов для вывода после лексического выбора. Этот буфер
Считается, что он работает как при воспроизведении речи, так и при задачах кратковременной памяти.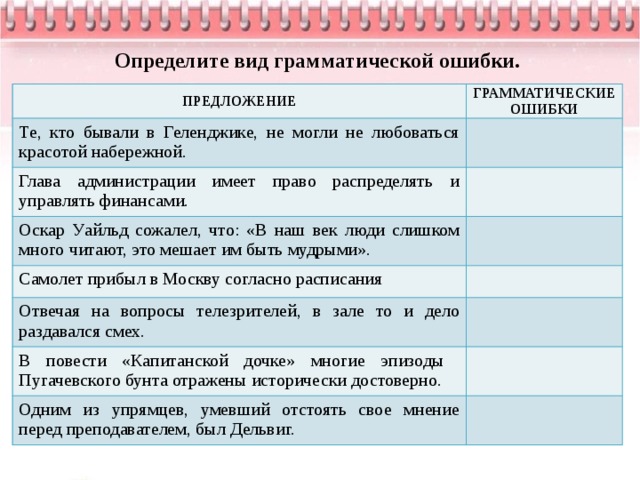
[Однако] Шаллис и Баттерворт (1977) сообщил об одном случае тяжелого
нарушение слухо-вербального STM без сопутствующего увеличения
нерешительность речи. Наиболее правдоподобной интерпретацией этих результатов является
что, против Morton, буфер, используемый в задачах STM, не используется в
речь .» (Баттерворт, 1980, стр. 165-166; курсив оригинала; полужирный
курсив добавлен)
2.3
Данные о развитии
Наконец, MacWhinney и
Osser (1977) приводит некоторые данные о развитии. Они
изучили 20 британских пятилетних детей и проанализировали их нерешительное поведение с помощью
пол и социальный класс. Они пришли к следующему выводу…..
»
Первым крупным результатом этого исследования стало выявление трех основных
Функции планирования: предварительное планирование, совместное планирование и
избегание излишней вокализации. Стили словесного планирования отражают
основные различия в когнитивной обработке. В основе всех трех планов
функция, однако, является одной центральной общностью — вербальное планирование требует времени.
Пока говорящий пытается сообразить, что сказать и как сказать,
разговор продолжается. Учитывая это неизбежное движение вперед во времени и его
собственные проблемы в формулировании своего высказывания, говорящий может сделать одно из двух
вещи. Он может попытаться полностью сформулировать то, что собирается сказать, прежде чем
говорит это. В качестве альтернативы, он может начать говорить и надеяться, что сможет понять
его высказывание в СМИ рез. Делает ли он паузу изначально или пытается исправить
вместе продолжающееся предложение, у него есть еще один вариант. Он может либо использовать
излишней вербализации, чтобы скрыть свои паузы и ошибки, или он может просто
не шумите. Анализ главных компонент в этом эксперименте показывает
что 13 феноменов колебаний, рассмотренных в этом исследовании, можно сгруппировать в эти
три функциональные категории: совместное планирование, предварительное планирование,
и избегание излишней вербализации. […..] Второй основной результат
это исследование показало, что у 5-летних детей различия в вербальной
функции планирования больше связаны с полом, чем с социальным классом. Мальчики были
Мальчики были
оказалось, что они больше занимаются совместным планированием, в то время как девочки больше
использование предварительного планирования. Более того, мальчики чаще использовали лишние
вербализации, чем девочки» (Маквини и Оссер, 19 лет).77, p984)
3 — Лексический
Модели конструкции
В этом разделе мы более подробно рассмотрим
плюсы и минусы лексического поиска …..
3.1
Теория распространения-активации лексического поиска
Рассмотрев множество потоков доказательств
тогда доступный ему, Делл (1986) предложил «распространение-активация».
Теория» лексического поиска. Вот основная нить его рассуждений…..
»
Принципиальное допущение теории состоит в том, что на каждом уровне представление
предложение, которое будет произнесено, строится. Таким образом, запланированное высказывание будет существовать
в разное время как семантический, синтаксический, морфологический и фонологический
представление. Теория описывает построение последних трех
Теория описывает построение последних трех
представления. […..] Построение представления на каждом уровне
происходит одновременно с другими уровнями [т.е.
параллельная обработка — Ред.], при этом скорость обработки зависит от факторов
присущие уровню и от скорости обработки уровня сразу
над ним. […..] Основная идея теории состоит в том, что помеченные узлы
составляющие более высокое представление активируют узлы, которые могут использоваться для
непосредственно более низкое представление через механизм распространения-активации.
нижнее представление строится как порождающие правила, связанные с
этот уровень создает фрейм или упорядоченный набор категорий, а правила вставки
заполнить прорези рамы […..]. Когда элемент выбран для слота, он
становится частью развивающегося нижнего представления и, таким образом, получает свой тег.
Таким образом, принципиальный механизм перевода информации из одного
репрезентация другому является распространением активации через лексикон.
[…..] Когда узел имеет уровень активации больше нуля, он отправляет
пропорция его уровня активации ко всем подключенным к нему узлам (распространение). Этот
пропорция не обязательно одинакова для каждого соединения. Когда активация
[достигает] своего узла назначения, он добавляет к текущему уровню активации этого узла
(подведение итогов). […..] Предполагается, что активация затухает экспоненциально [со временем]
к нулю. Эти операции — распространение, суммирование и распад — применимы ко всем
узлов в лексической сети всегда, независимо от того,
узел является частью представления (помеченного или нет). […..] Один из важных
предположения относительно распространяющейся активации в теории состоит в том, что все
соединения двухсторонние. Если узел A соединяется с B, то B соединяется с A. Учитывая
характер связей и иерархическая структура лексического
В сети каждое соединение можно классифицировать как возбуждающее «сверху вниз» или как возбуждающее «снизу вверх». Для каждого соединения сверху вниз
Например, от конкретной морфемы к определенной фонеме существует
соединение снизу вверх в обратном направлении. Эти связи снизу вверх
Эти связи снизу вверх
обеспечивать положительную обратную связь с более поздних уровней на более ранние и играть решающую роль
в теории. Их наличие делает обработку в сети высокоэффективной.
интерактивный [и] генерирует некоторые неочевидные прогнозы. […..] Строительство
Представления: В этом разделе я описываю, как строится нижнее представление.
при более высоком представительстве. Первая важная концепция — это концепция текущего .
узел . Это тот элемент представления более высокого уровня, который находится в
процесс переноса в соответствующие позиции непосредственно ниже
уровень. […..] Когда начинается построение нижнего представления,
Текущий узел — это тот узел более высокого представления, который помечен как первый.
: Начальным этапом перевода является активация текущего узла .»
(Dell, 1986, стр. 287-288; курсив оригинала; выделение жирным шрифтом)
Большой вопрос, конечно, в том, какие процессы
пойти не так, чтобы произвести данную ошибку, и Делл просто ответил, что «нет
виноват один процесс» (стр. 289). Речевые ошибки просто естественны.
289). Речевые ошибки просто естественны.
последствия того, как устроено сознание. Таким образом…..
«Для
например, при планировании высказывания многие понятия правомерно
активизируются, которые на самом деле не появляются в высказывании. Этот
фоновая активация может включать в себя активацию концепций, которые были либо предпосылками,
или выводы, которые были необходимы в семантическом и прагматическом планировании
высказывание. Например, если бы кто-то сказал Не могли бы вы закрыть дверь?, можно было бы
конечно, обработали предположение, что дверь была открыта. Как результат
концепция для открытый может быть активна, и из-за распространения
активация, узлы слова, морфемы и фонемы, связанные с [этим], будут
активироваться, что может привести к скольжению Может
вы открываете, то есть закрываете …..» (Dell, 1986, стр. 291; курсив оригинала)
Данные корпуса ошибок о расположении ошибок
тоже важны…..
«В
в целом, предметы с большей вероятностью будут перемещаться на короткие расстояния. неправильный порядок
неправильный порядок
звуки и морфемы стремятся перейти к соседним по содержанию словам, которые находятся в
ту же фразу (Бумер и Лейвер, 1968; Гарретт, 1975; Маккей, 1970). Неправильно упорядоченные слова перемещаются на большие расстояния, возможно, потому, что
фрагменты планирования на синтаксическом уровне больше, или потому что слова могут
перемещаться только в соответствующие синтаксические слоты (Garrett, 1975)» (Dell, 1986,
p293)
4 — Модульный
Модели производства речи
Теория Делла в первую очередь касается поиска слов.
на микроуровне. Он принимает базовую двухстадийную теорию и выделяет четыре
уровни представительства на этих этапах, но, хотя это может многое сказать
о том, что может происходить на нейронных уровнях, он не полностью затрагивает
модульность обработки. Другие работники придерживались более макроскопического взгляда,
и не только пытались сопоставить модули и процессы, вовлеченные в речь
производства, но начали продвигаться вверх в области прагматики.
В СТОРОНЕ: Праксис и прагматика
на самом деле имеют один и тот же лингвистический корень, а именно греческое слово prassein = «делать», через его производные praxis
(«делать») и прагма («дело»). Дефекты практики
известная как диспраксия . Мы уже имели дело с
длина с иерархией двигателей под несколькими отдельными заголовками. За
Например, это выходная ветвь стандартной А-образной модели иерархии управления.
Для конкретных примеров см. Craik (1945), Франк (1963) и Норман (1990) по истории двигательной иерархии в целом.
см. нашу электронную газету
на тему «Моторная иерархия»,
а для ознакомления с теориями биологического моторного программирования см. нашу электронную статью
по теме «Моторное программирование». А также
моторная иерархия для речи является одним из выходных звеньев стандарта.
Х-образная модель психолингвистического транскодирования. См., например, Эллис (1982), Эллис
и Янг (1988), а также Кей, Лессер и
Кольтхарт (1992). Для истории
Для истории
макет этой модели см. в нашей электронной статье
в разделе «Модели транскодирования».
В этом разделе мы рассмотрим некоторые
самая влиятельная из этих модульных моделей.
4.1 Очень ранняя модель производства речи Лордата
бумага. См. Лордат (1843 г.).
4.2 Прочее Раннее
Speech Production Models
Лордат был первым
многих моделей речи 19-го века, из которых следующие могут быть
стоит бегло просмотреть, если вас интересуют исторические аспекты предмета…..
Вернике (1874)
Куссмауль
(1878)
Лихтхайм
(1885 г.) (до сих пор является стандартной моделью медицинского образования 21 века)
Фрейда (1891 г.)
4,3 Шеннона
Идеализированная коммуникационная модель
В конце 1940-х гг.
инженерные аспекты связи. Это привело к
специалисты по телекоммуникациям свободно заимствуют из афазиологии
литературе и, в свою очередь, к психолингвистике, заимствовавшей многое из
полученный словарный запас в течение следующего десятилетия [в частности, такие слова, как
кодирование , информация , рабочая память , отношение сигнал/шум
соотношение и обратная связь ]. Инженер, который больше всего сделал для систематизации
Инженер, который больше всего сделал для систематизации
то, как мы смотрим на коммуникацию и ее неудачи, было Клодом Шенноном, затем с
Телефонная компания Белла [более полную историю можно найти в нашей электронной статье о «Шеннонианской теории коммуникации», если интересно].
4.4 Модель «Генератор высказываний» Фромкина
В 1950-е годы возрос интерес к
психолингвистические эксперименты, с основными работами Джорджа Миллера (Miller,
1951), Колин Черри (Черри, 1957) и Роджер Браун (Браун, 1958). Этот
Эксперименты дополнялись расширяющейся литературой по
психолингвистическое воздействие повреждения головного мозга во главе с Гарольдом Гудглассом (1920-2002) и Норманом Гешвиндом
(1926-1984). Эта основа затем породила ряд объяснительных моделей.
по психологии в целом. Дональд Бродбент стал одним из ведущих теоретиков
для избирательного внимания Джон Мортон сделал то же самое для модульного языка
обработки, Аткинсон и Шиффрин проделали то же самое с кратковременной памятью, а Алан
Baddeley добавил оперативную память. Стержневая работа в области речи
Стержневая работа в области речи
постановка Фромкина (1971, 1973) «Высказывание
Генератор» модели , который во многом воскресил Лордата.
Схема вещей XIX века с последующим шестиэтапным объяснительным анализом
…..
Стадия 1 Обработка — Семантическая система: Здесь впервые создается значение, которое необходимо передать.
Стадия 2 обработки — синтаксическая система:
определяется структура слота.
Стадия 3 Обработка — Лексическая система: Здесь из лексикона извлекаются содержательные слова, чтобы помочь
придать форму развивающемуся предложению.
Стадия 4 Обработка — Просодическая система: Здесь определяется подходящий интонационный рисунок.
Этап 5
Обработка — Фонологическая сборка: Это
где служебные слова [глоссарий]
вставляются в ключевых точках формирующейся структуры предложения, а затем
абстрактные звуки, присоединяемые к словам и морфемам, когда они занимают свое место
внутри каждого пункта.
Стадия 6 Обработка — Фонетическая система: Здесь конкретные звуки присоединяются к абстрактным звукам, и
начинается активация мышц.
Упражнение 4 — Итак Мост |
4,5 Гаррета
Speech Production Model
Это предмет отдельного разговора.
бумага. Увидеть Гаррета
(1990). [В двух точках своей модели Гарретт показывает два процесса,
с различными аспектами обработки одновременно — таким образом, в некотором роде
к размещению шести процессов всего в трех модулях обработки. ]
]
4.6
Современная модель производства речи Баттерворта
Рисунок на обоих Fromkin
и Garrett, Butterworth (1985) предлагает блок-схему, аналогичную схеме Гаррета, в
в котором идентифицируются следующие «системы или модули обработки» …..
Семантическая система: Это «обработка этапа 1» Фромкина, как определено выше.
Баттерворт рассматривает это как передачу информации «следующим трем системам».
параллельно» (стр. 68).
Синтаксическая система: Это «Обработка стадии 2» Фромкина, как определено выше.
Баттерворт рассматривает его как получение первого из трех потоков
информацию, выходящую из семантической системы, и как использовать эту информацию для
строить подходящие конструкции предложений и предложений.
Лексическая система: Это «обработка стадии 3» Фромкина, как определено выше.
Баттерворт расценивает это как получение второго потока информации, исходящего
семантической системы, и как с помощью этой информации подобрать подходящие слова
«из инвентаря — лексикона — словоформ» (стр. 69).
69).
Просодическая система: Это «Обработка Стадии 4» Фромкина, как определено выше.
Баттерворт расценивает это как получение третьего потока информации.
семантической системы, и как с помощью этой информации выбрать
соответствующий интонационный контур» (стр. 69).
Система фонологической сборки: Это
это «Обработка Стадии 5» Фромкина, как
определено выше. Баттерворт рассматривает это как создание «фонематической цепочки».
с синтаксическим заключением в скобки».
Фонетическая система: Это «этап 6 обработки» Фромкина, как определено выше.
Баттерворт считает, что это результат работы Фонологической ассамблеи.
системы, а затем генерировать подходящие команды двигателя. Это точка в
в котором абстрактные фонемы начинают превращаться в конкретные звуки [глоссарий].
Это также точка, в которой начинается коартикуляция.
место.
Рис. 2.
Если эта диаграмма не загружается . http://www.smithsrisca.co.uk/PICbutterworth2985.gif |
Перерисовано с |
 Баттерворта
Баттерворта 68; Рисунок 3.1). Этот рисунок
68; Рисунок 3.1). Этот рисунок4.7 Модели школ Levelt
Levelt (1989) опубликован
большая монография по производству речи под названием «Говорение: от
Намерение артикуляции». Как глава Института Макса Планка для
Психолингвистика, одним из его главных пунктов было рассмотрение разницы между
«лексическое кодирование» , поиск (и создание при необходимости)
слов для выражения мыслей и «синтаксическое кодирование» ,
поиск и определение последовательности слов для выражения идей …..
«Но
языки сильно различаются по степени использования [лексических
кодирование]. В то время как грамматическая кодировка носителя турецкого языка состоит в основном из
часть такого лексического кодирования, говорящий по-английски крайне «консервативен»
в том смысле, что он обычно использует слова, которые часто слышал в прошлом. За
носителю английского языка лексическое кодирование играет второстепенную роль в грамматическом
кодирование; действие находится в синтаксическом кодировании. Теория говорящего должна,
Теория говорящего должна,
конечно, охватывают оба вида грамматического кодирования. Собственно говоря,
однако почти ничего не известно о психологии лексического
кодирование.» (уровень, 1989, p186)
В попытке пролить свет на процессы
лексического кодирования Левельт много сделал для популяризации
использование термина «лемма» [см. предыдущее обсуждение, раздел 1.3]. Таким образом …..
«…..
с точки зрения языкового производства
лексическую статью можно разделить на две части: ее лемму и ее форму.
Информация []. Это теоретическое различие может быть распространено на ментальное
лексика в целом. Можно сказать, что леммы находятся «в лексиконе лемм», а морфофонологические формы — «в лексиконе форм». Каждый
лемма «указывает» на соответствующий ей вид. […..] семантическая
информация в лемме указывает, какие концептуальные условия должны быть
выполняется в сообщении для активации леммы; это лемма означает .
Эти условия могут быть сформулированы в том же пропозициональном формате, что и сообщения.
[…..] синтаксическая информация леммы определяет синтаксический элемент
категория, присвоение ей грамматических функций и набор диакритических знаков
переменные или параметры признаков» (Levelt, 1989).,
pp187-190)
Дальше по системе, Levelt
рассматривает процесс фонологического кодирования как работающий таким образом
…..
«Фонологические
кодирование — это процесс, посредством которого фонологические характеристики лексических единиц
извлекаются и сопоставляются с бегло произносимой последовательностью слогов.
Распаковка фонологических спецификаций слова и их использование для извлечения
соответствующие слоговые программы включают различные уровни обработки. Исследования
феномен кончика языка, в котором этот процесс фонологического
распаковка заблокирована или замедлена, поддержите эту точку зрения.» (Уровень,
1989, pp.
речедвигательная иерархия …..
Рисунок 3
Если эта диаграмма не загружается . http://www.smithsrisca.co.uk/PICdonald1991.gif |
Перерисовано с черно-белого |
 ): Эта модель была разработана на основе более ранних моделей Баттервортом (1980 г.,
): Эта модель была разработана на основе более ранних моделей Баттервортом (1980 г.,
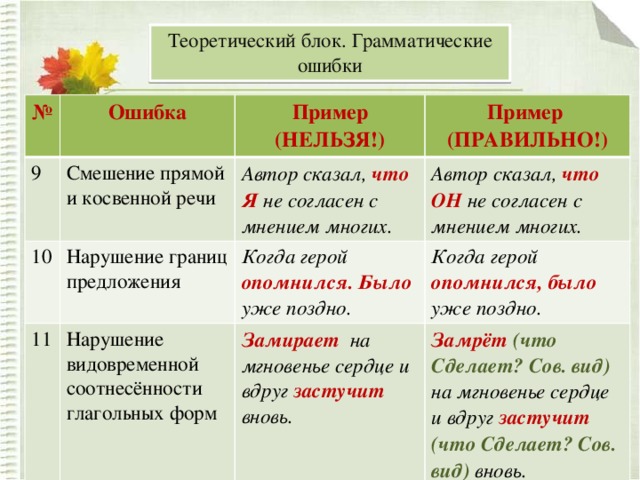 260; рис. 7.2). Это изображение Copyright 2003,
260; рис. 7.2). Это изображение Copyright 2003, Наконец, Levelt, Roelofs, and Meyer (1999) типичны для последних
предложение от исследовательского подразделения Levelt
…..
Рис. 4. Левелт, Рулофс и Мейер
Если эта диаграмма не загружается http://www. |
Перерисовано с |
 smithsrisca.co.uk/PICleveltetal1999.gif
smithsrisca.co.uk/PICleveltetal1999.gif
5 — Обратная связь в
Модели производства речи
Тема обратной связи была представлена в нашей электронной статье «The
Основы кибернетики», и особенно важно выступление
теория производства. Гракко и Эббс
(1987) среди многих указывают на то, что непрерывная речь предполагает непрерывную
обратная связь, то есть непрерывное выполнение двигательной программы
требует одинаково непрерывного потока сенсорной информации от мышц и
кожные ощущения в дыхательной, гортанной и орофациальной областях.
Аналогично, но на более высоком уровне анализа Levelt
(1989) посвящает целую главу теме самоконтроля и
самостоятельный ремонт. Среди видов отзывов Levelt сделок
с …..
* Я говорю то, что хотел сказать?
* Я так хотел сказать?
* Это то, что я говорю в обществе
соответствующий?
* Правильно ли я подбираю слова?
* Правильно ли я использую синтаксис и
морфология?
* Делаю ли я какие-либо фонологические
ошибки?
* Моя артикуляция справа
скорость и шаг?
Иными словами, успешное производство речи
постоянная борьба с ошибками, и эти ошибки могут появиться где угодно.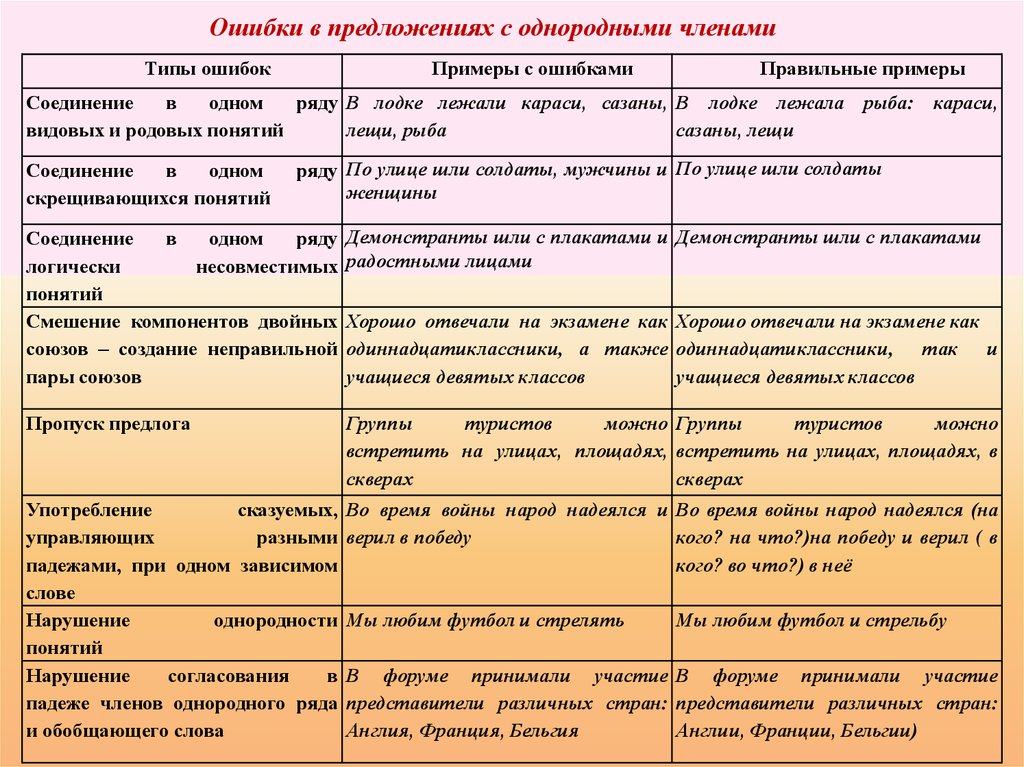
фразы, которые мы затем используем, чтобы прерывать и исправлять себя (такие фразы, как
«извините», «я имею в виду», «позвольте мне выразить это по-другому»,
и т. д.) известны в общем как «редактирование выражений» (Хоккет, 1967). Уровень (1989)
резюмировал вопрос таким образом …..
»
Главная особенность теорий редактора [мониторинга] заключается в том, что производственные результаты
возвращается через устройство, которое является внешним для производственной системы.
Такое устройство называется редактором или монитором . Это устройство может
быть распределенным в том смысле, что он может проверять промежуточные результаты в разных
уровни обработки. Редактор может, например, следить за построением
довербальное сообщение, уместность лексического доступа,
правильность синтаксиса или безупречность доступа к фонологической форме. Там
это, так сказать, бдительный маленький гомункул
подключено к каждому процессору .» (Levelt, 1989,
стр. 467-468; курсив оригинальный; добавлен жирный шрифт)
467-468; курсив оригинальный; добавлен жирный шрифт)
В этом разделе мы рассмотрим, как обратная связь и
редактирование изучено объективно …..
5.1 Раннее
Исследования
Ли (1951) впервые применил технику воспроизведения
речь человека в его собственные уши с переменной временной задержкой.
Вот как он описывает свой метод…..
«В
Для получения отсроченной речевой обратной связи необходимо вернуть
речь говорящего до его собственных ушей примерно через четверть секунды после того, как он сказал.
Лучше всего это сделать с помощью магнитной ленты [машины]. Тема
читает умеренно сложный текст в записывающий микрофон с
управление усилением воспроизведения на выключенной телефонной гарнитуре и нормальное чтение
узор установлен. Затем усиление воспроизведения в наушниках увеличивается.
пока речь субъекта не нарушится» (Ли, 19 лет).51, p53)
Используя эту экспериментальную установку, Ли обнаружил, что
было два типа общего эффекта. Испытуемые либо (а) замедляли и повышали голос, либо (б) начинали говорить
сбивчиво повторяя слоги в форме «искусственного заикания» .
То же явление возникло и у опытных тимпанистов.
чтение барабанного боя и нажатие клавиш опытными операторами азбуки Морзе. Ли приводит следующие конкретные примеры …..
алюминий ….. разлагается до алюминия -num…..
десять-девять-восемь-семь ….
деградирует до десять-девять-девять-восемь-семь…..
Ли интерпретировал эти результаты как свидетельство -кратного
Иерархия контурного управления с четырьмя уровнями обратной связи, как показано ниже.
…..
«Петля мысли»:
Верхний уровень управления высвобождает отдельные мысли для действия, а затем
отслеживает это действие на предмет успешного выполнения и завершения. Самый высокий уровень
петля обратной связи затем отслеживает вывод на предмет того, что в наши дни можно было бы назвать его прагматическим
уместность [строго говоря, ее «перлокутивное
эффект» ].
«Петля слов»:
Второй по величине цикл отслеживает производство речи на предмет точности выбора слов.
«Голосовой цикл»:
Третий высший цикл отслеживает производство речи на уровне целого слога для
Морфологическая точность.
Шарнирная петля»:
Наконец, нижний контур отслеживает речь.
производственная проверка правильности фонем
были использованы в каждом слоге.
Неразбериха при передаче между вторым
и третий уровень, который предположительно вызывает алюминий-номер
повторение слога. Однофонемных повторов не было. Вот это у Ли
собственный вывод …..
»
требуется удовлетворение на каждом этапе системой контроля; иначе
машина останавливается, повторяется или исправляется. Повторение предложений и слов
является произвольным для выделения, повышения ясности или исправления грубых ошибок.
Повторение слогов, вероятно, непроизвольное или рефлекторное, и именно при этом
этап проявляется искусственное заикание. Повторение фонем имеет
не было искусственно вызвано задержкой речевой обратной связи в [нашем] наблюдении
. ….» (Lee, 1951, стр. 54)
….» (Lee, 1951, стр. 54)
Эти ранние исследования были настолько убедительны, что Майсак (1966) прямо поставил кибернетику и речь
патологии в постели вместе в своей книге «Патология речи и обратная связь
Теория».
5.2 Редактирование и
Редактирование выражений
Motley, Camden и Baars
(1982) утверждал существование функции «предартикуляционный
редактирование» , следующим образом …..
«Редактирование
описывается как фаза речеобразования, наступающая после
фонологическая фаза (т.е. после
предстоящее сообщение развило свое фонологическое представление), но прежде
артикуляционная фаза, и которая работает, чтобы проверить или проверить лингвистические
целостность входящих последовательностей фонем. Редакция предположительно одобряет
последующая артикуляция тех фонемных последовательностей, которые лингвистически
соответствующий; но вето и попытки заменить те, которые лингвистически
аномальными, что препятствует их артикуляции» (Motley, Camden, and Baars, 19). 82, p578)
82, p578)
Motley et al затем провели около дюжины
исследования конца 1970-х и начала 1980-х годов, посвященные искусно индуцированным спунеризмам. Они
назвали свой метод SLIP — от «спунеризмов лабораторно-индуцированных
Предрасположенность», пояснив это следующим образом …..
«Субъекты
проинструктированы молча прочитать ряд тахистоскопически представленных
пары слов, произнося вслух определенные заданные «целевые» пары. Без ведома
субъекту, этим целевым парам слов непосредственно предшествует в серии
пары «вмешательства», разработанные так, чтобы фонологически напоминать искаженную версию предполагаемой цели. Например,
субъект может молча прочитать интерференционные элементы зарешеченное общежитие и куплены
собака непосредственно перед тем, как увидеть и попытаться артикулировать цель штопка
отверстие . Около 30% попыток испытуемых произнести целевую фразу приводят к
спунэризм — дверь амбара в этом примере. Наш самый типичный дизайн был
сравнить частоту аномальных и законных высказываний об ошибках;
аномалия определяется в соответствии с различными лингвистическими и квазилингвистическими
критериям» (Мотли, Камден и Баарс, 19 лет).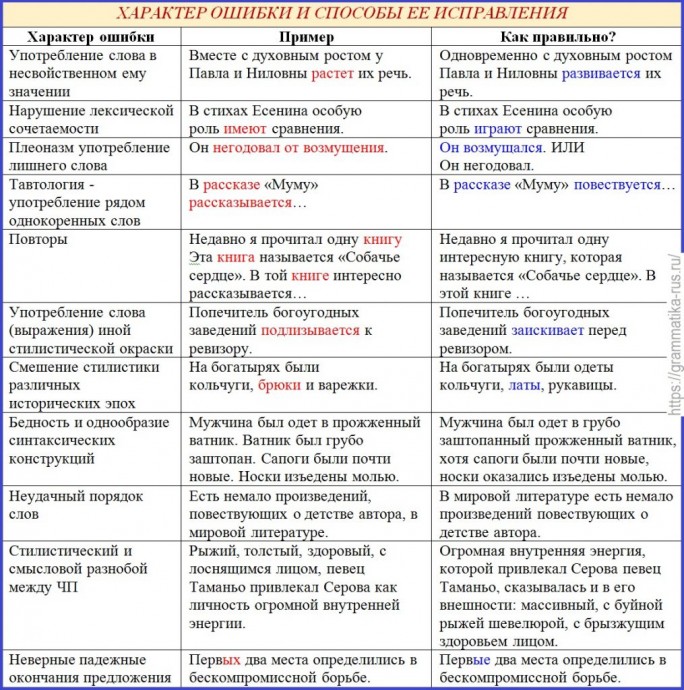 82,
82,
р579; курсив оригинала)
Затем они сравнили то, что они называют «коэффициентом проскальзывания».
дифференциал» между «законными» спунеризмами и
«аномальные» …..
«Наши
наиболее типичный результат состоит в том, что законных ошибок намного больше, чем аномальных. За
например, лексически допустимые ложные выражения SLIP, такие как чертов хам > сарай
дверь будет встречаться гораздо чаще, чем аналогичная, но лексически аномальная
один как мишень для дартс > Барт
дверь . [//] Этот дифференциал скорости скольжения [имеет]
была основной формой доказательства преартикуляционного
редактирование. То есть приведенный выше пример […..] можно рассматривать как доказательство
что когда субъект SLIP создает лексически допустимую фонемную строку,
строка разрешена для вывода; тогда как когда субъект конструирует
лексически аномальный потенциальный результат, на него наложено вето (редактированием), и его
артикуляция запрещена» (Motley, Camden, and Baars,
1982, стр. 579; курсив оригинала)
579; курсив оригинала)
Что касается лежащих в основе нейронных механизмов, Кроссон (1985) предлагает взгляд на производство речи с участием
Зона Брока, зона Вернике и другие
подструктуры таламуса и базальных ганглиев, связанные между собой циркулирующими
и рециркулирующие пути белого вещества, а также доставляющие как семантические, так и
фонологический мониторинг. Подробнее см. в отдельной статье Crosson.
(1985).
Упражнение 5 — Модель Levelt лишилась состоящих из двух частей высших функций Баттерворта. |
 Используйте свои навыки построения диаграмм, чтобы создавать большие,
Используйте свои навыки построения диаграмм, чтобы создавать большие,
6 —
Патологические состояния, связанные с дефектными системами биологического контроля
Теперь причина, по которой
важно для клиницистов то, что существует ряд очень хорошо
известные патологии общения — не в последнюю очередь заикание, диспраксия и
дислексия, которая на самом деле является кибернетическими проблемами в основе. Мы уже
о заикании говорилось в разделе 5.1, а вот некоторые другие
…..
6.1 Дислексия
В результате плохого контроля мышц головы/глаз
Дислексия – это неспособность обрабатывать зрительные
эффективно представить текст. Хотя на первый взгляд это проблема восприятия ,
сама сложность системы глазодвигательного контроля делает ее двигательной проблемой
также. Вы не можете читать, если не можете контролировать движение своих глаз. Когда
Вы не можете читать, если не можете контролировать движение своих глаз. Когда
читая этот текст, например, ваши глаза будут фиксироваться после каждых восьми
персонажей (примерно каждые полтора слова) (Райнер и Поллацек,
1989), и многие авторитеты (как правило, Павлидис,
1981/1985) считают, что дислексию развития можно объяснить дефектами
упорядочивание этих фиксаций для максимального усвоения информации. Дислексия развития
имеют характер движения глаз, отличающийся от нормального
читателей (Rayner and Pollatsek, 1989). Однако это
Фактор сам по себе не был сильно подтвержден. Действительно, Рейнер и Полласек придают большее значение работе Стейна и Фаулера (1982,
1984) выводы «Контроль вергенции»
проблемы у дислексиков. Вергентные движения – это
которые удерживают оба глаза в одном и том же центре внимания. В норме
читатели, два глаза двигаются «сопряженно»,
то есть они движутся с одинаковой скоростью и в одном направлении. Штейн
а данные Фаулера показывают, что примерно каждый шестой случай развития
дислексия может улучшить способность к чтению при лечении этой проблемы в
изоляция.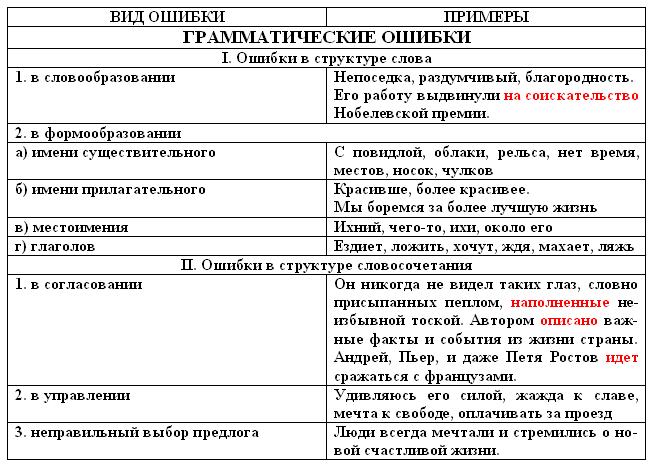
Что касается кибернетики управления глазами, то
система глазодвигательного контроля обслуживает различные биологически важные виды поведения
таких как поиск пищи и избегание хищников (Галиана,
1990). Поэтому он должен быть настолько же функционально сложным, как и
скелетно-мышечной системы он помогает направлять. Этот функционал предоставляется
за счет наличия комплекса контуров управления с прямой, прогнозирующей и обратной связью.
Работа. Начнем с того, что есть механизмы, управляющие автоматической фокусировкой.
объектива, бинокулярной вергенции и автоматического
закрытие зрачкового отверстия. Затем появляются дополнительные механизмы
управлять автоматическим позиционированием глаза относительно головы как головы
движется относительно тела и внешнего мира. Эти последние механизмы
предъявляют высокие требования к обработке информации вестибулярной системой, системой
который обрабатывает информацию, предоставленную полукругом
каналы внутреннего уха («лабиринт»),
детекторы баланса тела. Информация с полукруга
Информация с полукруга
каналы идут к стволу мозга по вестибулярной ветви
преддверно-улитковый нерв (CN VIII). Здесь он соединяется через вестибулярные ядра.
нижнего моста к мозжечку и множеству других компонентов
экстрапирамидная система. Хорошие обзоры по этой тематике можно найти в
Петерсон и Ричмонд (1988), Галиана (1990) и Бертоз, Граф и Видаль (1992).
6.2
Паркинсонизм
Двигательные расстройства, характеризующие
Болезнь Паркинсона условно связывают с поражением мышц
схема управления. Сам Винер сравнивал паркинсонический тремор с
колебания недостаточно «демпфированных» контуров управления (Винер, 1950), Флауэрс
(1978) винит в отсутствии предсказания Харрингтон и Хааланд.
(1991) винят в этом «дефицит центральной обработки», а Диннерштейн, Фригьези и Ловенталь (19).62)
виновата медленная, чем обычно, проприоцептивная обратная связь за разнообразие стандартных
Симптомы паркинсонизма, такие как ригидность, медлительность и нарушение координации.
6. 3 Обучение
3 Обучение
Трудности
Присутствуют многие категории трудностей в обучении
с неспособностью (среди прочего) эффективно общаться в
прагматический уровень. Это может быть облегчено в большей или меньшей степени путем
обучение тому, что Уильямсон (1992) описывает как навыки «обратного канала».
Они включают в себя широкий спектр как вокальных, так и не вокальных
реакции, такие как кивки, тряски, ворчание, выражение лица и т. д., чьи
Функция состоит в том, чтобы сообщить говорящему, в какой степени его/ее высказывания
разбираются. [Это, по определению, должно работать на пределе возможностей Ли.
петля обратной связи уровня — петля «мысли».]
6.4 Аномия
Аномия – неспособность подобрать слово-имя для
что-то, что иначе прекрасно понимается. это очень распространено
клинический признак, и может возникать при различных болезненных процессах, как очаговых,
и диффузный, хотя он особенно связан с травмами
угловая извилина (Маршалл, 1980). В простейшей форме аномия проявляется как
трудность с конфронтационными задачами именования , хотя способность
описывать понятие по касательной в надежде, что это компенсирует
отсутствие собственного имени часто сохраняется. Таким образом, пациент может сказать
Таким образом, пациент может сказать
«Вы режете им еду», если он / она не может получить доступ к слову
«нож». Эта уловка известна как иносказание . это даже
возможно, что потерянное целевое слово будет включено в обиход даже
хотя сам по себе он был недоступен, например: «Я бы использовал его, чтобы расчесать
мои волосы» в качестве замены слова «гребень» (Benson, 1979).
Маршалл (1980, стр. 62) приводит хороший пример трудностей с поиском слов в
пациент описывает картину …..
«‘Это
….. вы знаете, ….. очень
очень похоже, что они попали на ….. на что-то очень
много. Я не говорю, что это правильно, но это как э
э …..
Я не могу этого сказать, но я могу просто ….. да,
это может быть так, может быть немного похоже на это, да. [так далее.]
(Маршалл, 1977)».
Что касается объяснительных моделей,
нам повезло, что изначально они были составлены с учетом аномии. Ведомый
по массе клинических данных, накопленных с 1860-х гг., всех современных
модели последовательно отделяют представление от выбора слов, то есть они
отделить семантическую систему от выходных словарей [это
принципиальное различие между лингвистическим и психолингвистическим употреблением
словарная лексика]. Гнозис — это то, что делает семантическая система, а именование — это то, что
Гнозис — это то, что делает семантическая система, а именование — это то, что
речевой вывод лексикон делает. Сам Мортон связывает аномическую афазию с проблемами
двигаясь наружу от семантической системы к выходному лексикону, точно так же, как
создатели диаграмм девятнадцатого века до него. Затем он противопоставляет это оптическому
афазия, когда есть проблемы с продвижением внутрь семантической системы
из словарей визуального ввода (Мортон, 19 лет).85).
Но аномическая афазия — не единственное состояние в
какое слово найти трудности найдены. Benson (1979) выделяет не менее
чем девять подтипов, из которых следующие пять являются в некоторой степени афазными …..
(a) Word Production
Аномия: Это противостояние
фонематическая подсказка
(или «подсказка»). Если пациенту дается первая буква
целевое слово, все слово внезапно становится доступным. Пациенты могут показаться
«знать» имя цели, но не может инициировать ее производство в
все, или вместо этого создайте неологизм. (Таким образом, это условие
(Таким образом, это условие
аналогично феномену «кончика языка», обсуждаемому в разделе
1.3 выше.)
(b) Выбор слова
Аномия: Это еще один
конфронтационный дефект именования, но на этот раз он обычно не устраняется
подсказка Гнозис не поврежден (поскольку пациенты могут сразу указать на объект
в вопросе, если назвать его имя), а в остальном разговорная речь беглая
и без усилий.
(c) Семантическая аномия: Это неспособность использовать имя объекта в качестве
ментальный символ. Внешне похож на (б), но пациенты не могут указать на
рассматриваемый объект, если ему сказали его имя.
(d) Для конкретной категории
Аномия: Это аномия для
определенный концептуальный класс объектов. Встречается довольно редко, тем не менее имеет
побудил таких авторов, как Барон (1976) и Олпорт
(1985), чтобы описать семантический словарь как имеющий различные области (или
«зоны» или «домены» и т. д.), каждая из которых связана с определенным
класс атрибутов. Таким образом, изобразительные атрибуты объекта, цветовые атрибуты,
Таким образом, изобразительные атрибуты объекта, цветовые атрибуты,
позиционные атрибуты, атрибуты «движение глаз-головы-тела» и даже
обонятельные и вкусовые признаки, считаются хранящимися в отдельных частях
одна большая распределенная система инграмм.
(e) Зависит от модальности
Аномия: Это аномия для объектов
представлена в одной модальности, но не в другой (например, визуальной, а не
слуховой). Тем не менее, вероятно, лучше всего рассматривать его как зрительный (или слуховой).
афазия, а не аномия как таковая.
6.5 Аграмматизм
Этот термин происходит от Куссмауля
(1877) и относится к афазическому состоянию типа Брока.
характеризуется проблемами с ракурсом предложения и морфологией слов.
Однако ракурс не является случайным, поскольку он включает в себя пропуск многих/всех
служебные слова предложения (артикли, союзы, местоимения, предлоги,
и вспомогательные глаголы) и флективные окончания слов (-s, -ed,
-ing). Конечным результатом является то, что известно как телеграфный
речь , последовательность слов, состоящая в основном из существительных, но разбитая
окказиональный глагол и определитель (Goodglass and Menn, 1985). Союз «и» часто
Союз «и» часто
пощажены, хотя это может свидетельствовать скорее о стратегии исправления, чем о подлинном когнитивном
способность. Вот несколько примеров…..
«Первый
утром пей кофе, подмети и иди в поле, днём такую таблетку, раз и
иди в поле…» (Heilbronner,
1906 г., цитируется у Маккарти и Уоррингтона, 19.90.)
«Золушка
…бедняжка… гм… намыла ее… вымыла пол, гм,
опрятный… бедный, гм… ‘приобрел… Си-сестрички и
мать … мяч. Мяч, принц, гм, башмак … [подсказка
продолжить] Почистил и э-э вымыл и э-э … опрятно, э-э, сестры и мать,
князь, нет, князь, да. Золушка зацепила принца. (смеется).
Гм, гм туфелька, гм, двенадцать часов, мяч /pInaSt/ ,
закончено» (Шварц, Лайнбаргер,
и Saffran, 1985, стр. 84; Пациент «МЕ».)
Дополнительные примеры у Маккарти и
Уоррингтон (1985).
Что касается основной анатомии
Маккарти и Уоррингтон (1990, стр. 185) заключают, что «[симптомокомплекс Брока] часто связан с
относительно широко распространенные поражения, поражающие обе передние речевые области (лобная
доля), более глубокие структуры (островок), а также передняя часть височной доли
повреждение», а что касается лежащей в основе обработки, Колк, Ван Грунсвен и Кейзер
(1985) и Каплан (1985) явно связали аграмматические
условия модели Гарретта (которая, как мы напомним, изначально
разработан на основе данных об ошибках речи у нормальных испытуемых). Они заключают
Они заключают
что внутренний язык по своей сути телеграфичен в лучшие времена, по крайней мере
на всех стадиях до функциональной стадии Гарретта.
Аналогичная аргументация была разработана
совсем недавно Гродзинский (1990), который
подошел к аграмматизму как лингвист. Он описывает
поверхностная речь, лишенная как нелексических окончаний, так и управляемых предлогов.
Действительно, в отличие от аномий, единственный
аграмматические пациенты оставил с
способность к именованию! Однако вряд ли будет возможен окончательный ответ
до тех пор, пока мы не узнаем больше о нормальном воспроизведении речи, то есть пока мы
иметь лучшие модели производства речи для работы. (И, в частности, модели
которые могут связать неопровержимые факты лингвистической теории с более продвинутыми
теории структуры семантической памяти.)
Упражнение 6. Симуляция аграмматизма 1 Переписать предыдущий абзац на |
 Прочитайте остаточный текст вслух.
Прочитайте остаточный текст вслух. 6.6 Жаргон
Афазия
Термин «жаргонная афазия» происходит от Alajouanine, Sabouraud, and Ribaucourt (1952) и представляет собой «редкое и впечатляющее
проявление афазического состояния» (Butterworth, 1985, стр. 61).
контраст с аграмматизмом, фонологией и просодией
основного языка сохраняются, как и многие правила морфологии (
бессмыслица часто правильно сопоставляется по числу, падежу и роду). В
кроме того, пациент часто находится в блаженном неведении о нарушении. Три
были идентифицированы различные синдромы (Баттерворт, 1985)
…..
(a) Семантический жаргон: Здесь «употребляемые слова, хотя и реальные,
семантически неуместны, иногда до такой степени, что кажутся лишенными
их нормальное значение» (Баттерворт, 1985, стр. 63). Вот образец: « Экспериментатор:
Что значит «куй железо, пока горячо»? Пациент: Лучше быть
хорошо и на почту и в почтовый ящик и на рассылку по почте и
обследование и директор.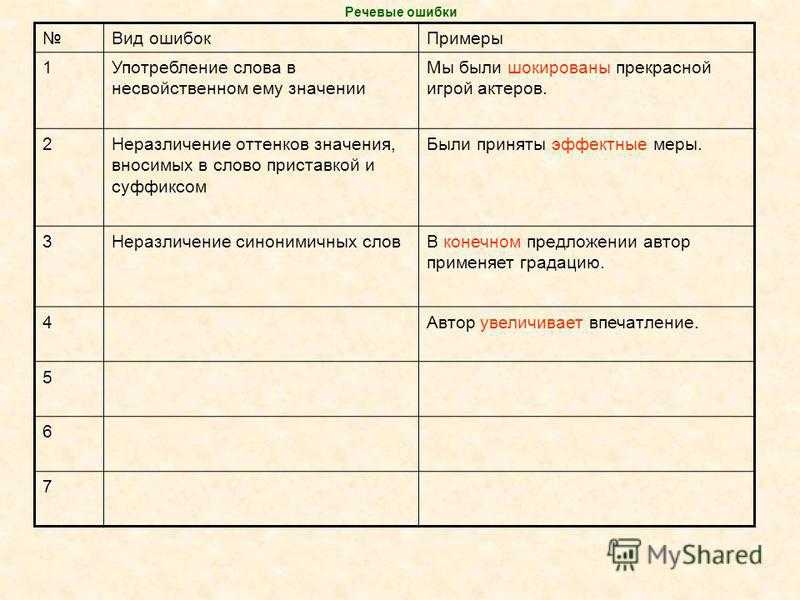 Южные железные дороги очень хорошие и Лондон
Южные железные дороги очень хорошие и Лондон
и Шотландии» (Кинсборн и Уоррингтон, 19 лет).63;
Пациент «EF», цит. по Buckingham, 1985).
(б) Неологический
Жаргон: Здесь речь включает
выдуманные слова — слова, не найденные в словаре. Баттерворт (1979) сообщает
что неологизмы использовались как существительные (61%), глаголы (20%) или прилагательные (15%) —
категории, известные как содержательные слова, где каждое слово должно быть выбрано из
большое количество вариантов. Неологизмы были редки в контексте служебного слова (4% в
общий). Вот образец: «Человеку задают вопрос: «Кто бежит
магазин сейчас? Он отвечает: «Я не знаю. Да бик,
э-э, да, я бы сказал, что мик дайсис нозис или чиктерс. Конечно, я
также пропустили на Carfter Teck.
Вы знаете, что это такое? У меня есть жетон на ингиш.
Они были поджарены sosilly. Они бы
были помещены в myafa и сделаны palis
и, э-э, мядакал сенда
ты. Это я алордисдус. Это делает anacronous senda'»
(Бэкингем и Кертес, 19 лет. 76, цитируется у Маршалла,
76, цитируется у Маршалла,
1980, стр. 62).
(c) Фонематический жаргон: Здесь речь вырождается в последовательность
бессмысленные звуки, так что определить границы слов становится невозможно.
Некоторые фонотактические правила остаются в силе, например,
кластеры «tr», «nkr»,
«ул» и «мбр»
в следующем образце: «Когда его попросят прочитать предложение , оно должно быть
во власти Колледжа проверять или не проверять любого лицензиата,
до его приема в товарищество, как они сочтут нужным , он
выдал следующее: А что в теметере
от trothotodoo к majorum
или что emidrate ein einkrastrai mestreit to ketra totombreidei to ra fromtreido as the kekritest » (Перекман
и Браун, 1981, стр. 178; курсив оригинал.)
Упражнение 7. 1 2 3 |
 Прочитайте получившийся «смысловой жаргон» вслух.
Прочитайте получившийся «смысловой жаргон» вслух. Что касается лежащей в основе анатомии, Kertesz (1981) рассмотрел десять случаев неологической
жаргона в деталях и обнаружил существенную закономерность в основных поражениях. Он
пришел к выводу, что «наиболее последовательно пораженными областями являются надмаргинальная извилина, задняя теменная покрышка,
нижняя теменная долька, первый отдел первой височной извилины,
задняя височная покрышка (planumtemporale) и угловая извилина» (Кертеш, 1981, стр. 100).
6.7 Диспраксия
речи
Учитывая наше предыдущее определение практики,
Отсюда следует, что сутью диспраксии должно быть нарушение способности
инициировать произвольные движения — неспособность двигать языком, чтобы облизать губы
например, по приказу.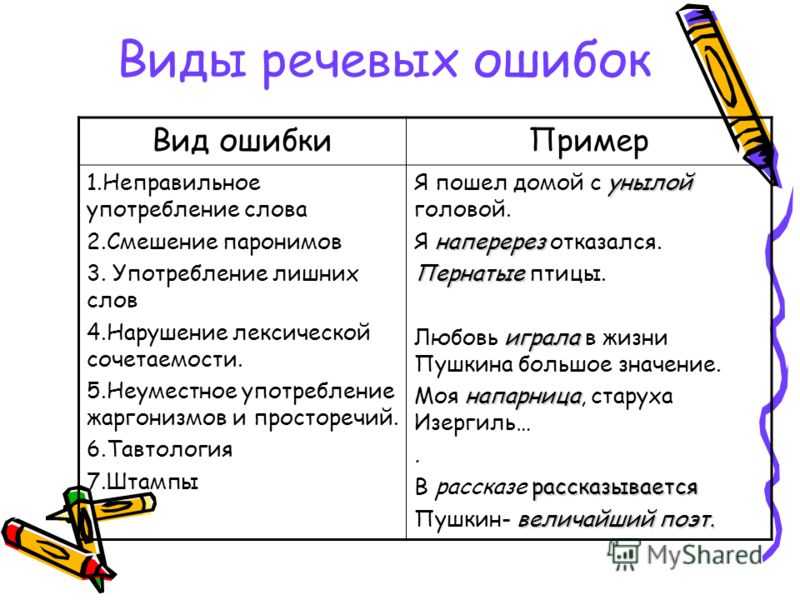
В СТОРОНЕ — PRAXIS VS REFLEX: It
важно понимать, что дефект является исключительно одним из инициирующих
движения, а сами мышцы и двигательные системы не повреждены. Если
инициация рефлекторная или никакая невольная — слизывание меда с губ,
возможно — информация попадается при стандартной А-образной обработке
иерархии, а не вниз по ней, и движение может быть выполнено отлично!
Дефекты диспраксии были
впервые формально описан немецким афазиологом Лиепманном (1900, 1905), и его объяснение прижилось
близко к парадигме стадий производства речи, которую мы так много видели в разделах
3 и 4 выше. Пациенты, которые не могут мысленно представить наличие необходимого
движения считаются имеющими идеациональную апраксию ( идеаторише
apraxie ‘), пациенты, у которых может быть представление, но
не сообщают эту идею соответствующим двигательным системам, считаются имеющими
идеокинетическая апраксия (‘ идеокинетическая апраксия ‘),
и пациентов, чья двигательная система не может должным образом справиться с инструкциями
отправленные им, считаются имеющими кинетическую апраксию ( ‘кинетическую апраксию’ ).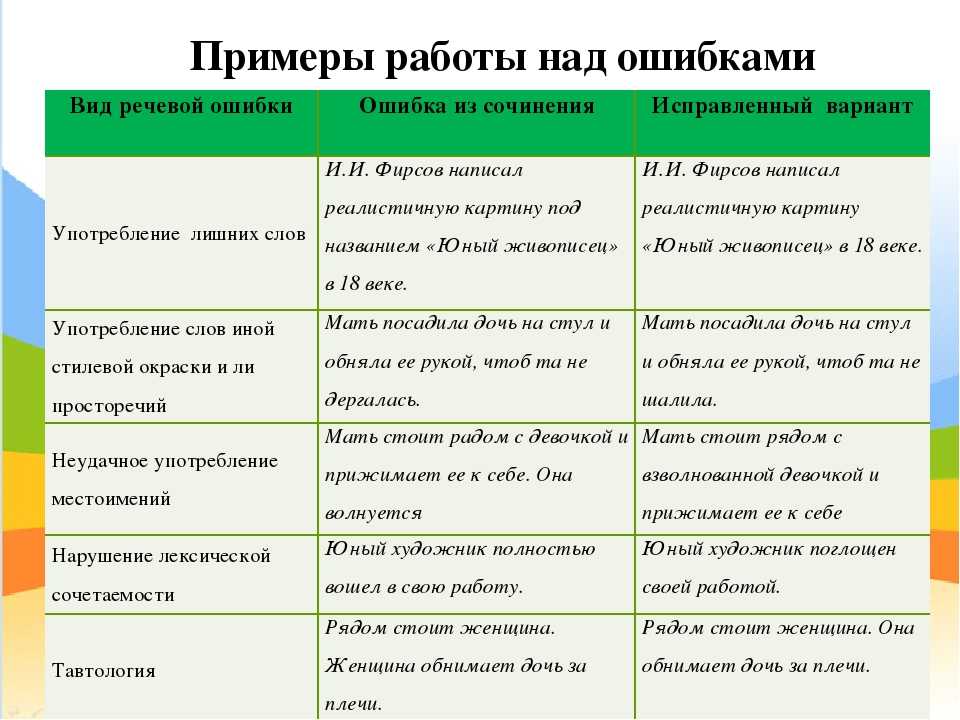
Впоследствии немецкий психиатр Клейст (1912) описал дефицит конструкционных
апраксия , при которой нарушена способность к организации действий в пространстве. Он
расценил это как еще один синдром отключения, на этот раз способности
для передачи информации между процессами пространственного анализа и процессами
добровольное действие. Яркое описание диспраксии
речь произносят Дарли, Аронсон и Браун…..
«Как
они говорят, они изо всех сил пытаются правильно расположить свои артикуляторы. Они
визуально и слышно нащупывают, пытаясь произвести правильную артикуляционную
позы и выполнить последовательность этих поз в формировании слов. Их
артикуляция часто не соответствует цели. Они часто признают, что не в себе
прицельтесь и постарайтесь исправить ошибку.
Тем не менее их ошибки повторяются, но они не всегда одни и те же; ошибки
в серии испытаний сильно варьируют. Поскольку пациенты изо всех сил пытаются избежать
артикуляционная ошибка путем тщательного программирования движений мышц, они замедляются,
распределяйте их слова и слоги равномерно и делайте на них одинаковое ударение.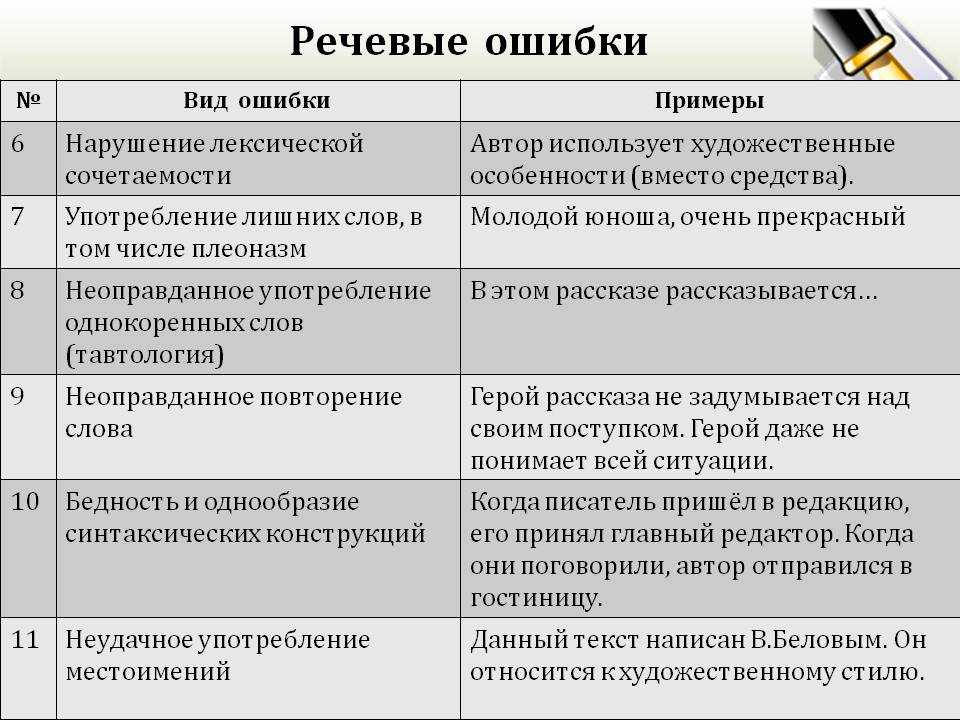 Таким образом
Таким образом
просодия их речи изменена так же, как и их артикуляция».
(Дарли, Аронсон и Браун, 19 лет.75, p250)
Фонемные замены, добавления, повторы,
и продления являются общими. Таким образом…..
«Я
ищу рисунок или изображение
то, что, по-видимому, является тор-нух-нер-нор-торнатиуд, назревающим в сельской местности. Это
имеющий nuh-nuhmediate и
пугающий ef-f-ff-fuh-feck на ярмарке фамильярная нумерация — — — шесть э-э
люди и af-ff-sss-uh-sh-suh-сортированные
ферма животных. Они быстро идут в подвал с sss-sor-sormb с
испуг в их а-а-а-глазах и в каждом их-
движение. (Дарли, Аронсон и Браун, 19 лет.75, стр. 250.
Подчеркивание указывает на ошибки, а дефис указывает на нерешительность.)
На языке теории управления подозрение
заключается в том, что основной механизм прямой связи дает сбой. Действительно, это лежит в основе
различие между планированием и исполнительным апраксией
принят такими авторитетами, как Майкл Крэри из
Центр медицинских наук Университета Флориды, Гейнсвилл. (Crary, 1993, со ссылкой на более раннюю статью
(Crary, 1993, со ссылкой на более раннюю статью
Рой, 1978). Схема Роя-Крари определяет
четыре подтипа расстройства …..
(а) Первичное планирование
Диспраксия: Это высокий уровень
дефект планирования и обычно связан с патологией лобных долей.
(b) Вторичное планирование
Диспраксия: Это более низкий уровень
планировочный дефект, возможно, дефект пространственной организации, а не
неспособность мыслить наперед в самом широком смысле. Обычно это связано с
теменно-затылочная патология.
(c) Единица Диспраксия: Это дефект, поражающий одну конкретную мышцу
система больше, чем остальные.
(d) Исполнительная диспраксия:
Это невозможность выполнить
движения, успешно прошедшие стадию планирования. Это обычно
сочетается с патологией премоторной области. По словам Роя: «….. хотя
пациент может планировать двигательную активность, так как лобные области не повреждены
и проводящие пути от лобной до премоторной области не нарушены, он
не может правильно выполнить последовательность движений из-за повреждения области
отвечает за вывод запланированной двигательной последовательности» (Рой, 19 лет). 78, стр. 197).
78, стр. 197).
Также из Университета Флориды Роти и Хейлман (1996) принесли
история замкнулась за счет явного перекрестного сопоставления
ранние описания на современную когнитивную нейропсихологическую модель (не
непохожий на нашего старого друга, модель PALPA). Смысл действий — это
то есть их полезность для организма при составлении его планов — видится как
опосредуется центральным хранилищем «семантики действий» , в то время как
поддерживающие физические атрибуты опосредованы вторичным массивом из «действие
лексиконы» . Это важное подтверждение транскодирования
школу, чтобы обнаружить, что их модели, основанные на дислексии и т. п., могут применяться столь же эффективно.
к человеческому движению в его самой широкой форме!
6.8 Дизартрия
речи
Прежде чем продолжить, учащиеся должны освежить в памяти
относительно основ двигательной системы [пересмотрите это сейчас].
Анатомия ствола мозга и черепных нервов [пересмотреть сейчас]
особенно важно, так как дифференциальная компоновка пирамидальной и
экстрапирамидные системы!
Дизартрия речи — это название, данное речи
трудности, возникающие из-за проблем с контролем вовлеченной мускулатуры. Немного
Немного
представление о требуемой точности можно получить из того факта, что язык и
движения губ в обычной речи должны быть скоординированы с точностью до 1/100
секунды и изготовлены с точностью до 1 мм (Netsell,
1986). Так что же происходит, когда эта точность размещения и тайминга начинает падать?
прочь? Ну для начала…..
«В
при дизартрии обнаруживаются признаки медлительности, слабости, нарушения координации или изменения
тонуса речевой мускулатуры. [Все] основные двигательные процессы — дыхание,
фонация, резонанс, артикуляция и просодия — задействованы по-разному. []
наиболее характерная ошибка больных дизартрией
неточное произношение согласных, обычно в виде искажений и
упущения» (Дарли, Аронсон и Браун, 19 лет).75, стр. 251.)
Ситуация серьезно осложняется, однако,
поскольку упомянутые выше двигательные механизмы (дыхание, фонация,
резонанс, артикуляция и просодия) контролируются тщательно продуманным
расположение спинномозговых и черепно-мозговых нервов. В результате существует несколько
В результате существует несколько
клинически различимых подтипов дизартрии. Дарли, Аронсон и Браун опознают
не менее шести, как теперь описано …..
(a) Вялая дизартрия: Этот тип дизартрии возникает в результате повреждения
уровень нижний мотонейрон . Два скопления нижних двигательных нейронов
значительный. Во-первых, имеется спинномозговых нерва, оттоков от обоих грудных
и поясничного отделов. Они иннервируют брюшные и межреберные мышцы,
включая диафрагму, и тем самым контролировать дыхательный аспект
фонация. Во-вторых, из нижней
мост и мозговое вещество. Из них CN V (тройничный), CN VII (лицевой), CN X (блуждающий) и CN XII (подъязычный) имеют сенсорные и моторные функции.
функции глотки и челюсти. Клинически характерными признаками являются мышцы.
слабость и гипотония, а также снижение или отсутствие растяжения
рефлексы. Состояние встречается в различных подтипах бульбарный паралич
(в зависимости от того, какой из черепных нервов поврежден).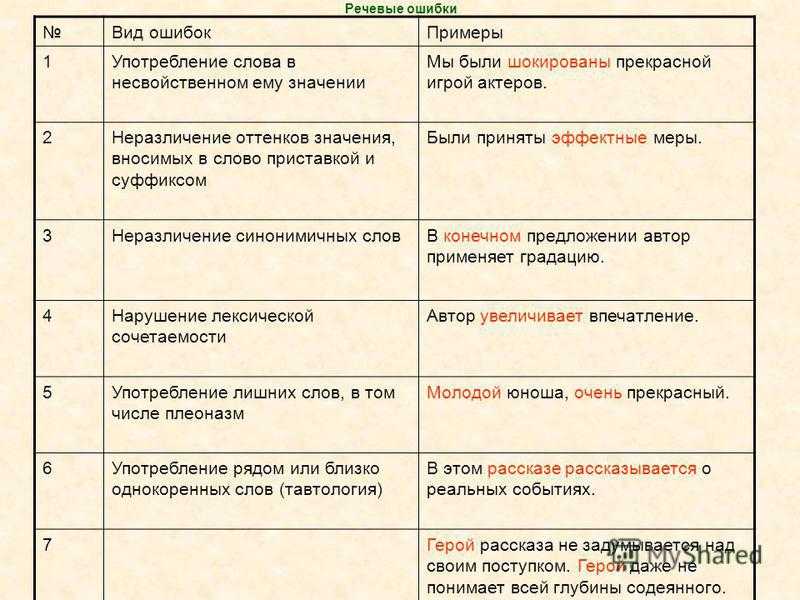 Речь представлена как
Речь представлена как
«медленный, гиперназальный и с придыханием, со сниженным
громкость и уменьшенную изменчивость высоты тона» (Netsell,
1986, стр. 41).
(b) Спастическая дизартрия: Этот тип дизартрии возникает в результате повреждения
уровень верхнего двигательного нейрона . В результате латеральные поражения
корково-спинномозговые пути будут представлены как контралатеральные дефекты, в то время как те,
корково-бульбарные тракты (не полностью перекрестные) будут проявляться как более мягкие двусторонние
слабость языка, губ или лица. Условие находится в том, что известно как
псевдобульбарный паралич (двустороннее кортикобульбарное поражение на уровне
верхний двигательный нейрон) и спастическая гемиплегия. Речь представляется медленной,
неясный и напряженный, как будто созданный вопреки сопротивлению.
описания «скрежетание» и «перетаскивание» также могут быть
столкнулся.
(c) Атактическая дизартрия: Этот тип дизартрии возникает в результате повреждения
мозжечковая система, чаще двусторонняя. Состояние встречается в, для
Состояние встречается в, для
например, Атаксия Фридрейха . Характерными чертами являются неточность и
неуклюжесть артикуляции, чередующаяся с отрывистыми речевыми периодами и
неожиданные изменения высоты звука.
(г) Гипокинетический
Дизартрия: Этот тип дизартрии
возникает из-за повреждения экстрапирамидной системы с вовлечением структур
например базальные ганглии. Клинически характерными признаками являются замедление
движение, ограниченный диапазон, ригидность и тремор в покое. Состояние найдено
в Болезнь Паркинсона и некоторые Болезнь Хантингтона . Речь
мягкий из-за плохой координации дыхания и фонации и дрожащий из-за
неэффективная «охота» голосовых связок. При закрытии гортани в конце концов
полностью терпит неудачу, тогда все голоса теряются и возможен только шепот.
(e) Гиперкинетический
Дизартрия: Этот тип дизартрии
также возникает при поражении экстрапирамидной системы, но с другим набором
выраженных признаков, а именно подергивания, тики, хорея, баллизм,
и атетоз. Состояние встречается у некоторых Хантингтон
Состояние встречается у некоторых Хантингтон
болезнь , синдром Туретта и хорея Сиденгама (подробнее
широко известный как Танец Святого Вита ). Речь представлена неуверенно и
беспорядочно прерывистым из-за нарушения упорядоченной фонации.
(f) Смешанная дизартрия: Это
Тип дизартрии возникает из-за многоочаговых или диффузных поражений, т. е.
те, которые повреждают более одной части двигательной системы. Условие
найдено в рассеянный склероз , и симптомы очень разнообразны, как
результат многоочагового характера основной патологии.
7 — Замечания
Наконец, стоит еще раз взглянуть на выступление
модели, указанные в разделе 4, в свете дефектов воспроизведения речи
вышеперечисленное. Аномии кажутся дефектами на уровне или
вокруг уровня лингвистического контроля, либо с наличием идеи в первую очередь,
или же с извлечением элемента из семантического лексикона, с помощью которого можно выразить
эта идея.